Referansearkitektur for deling av data i høyere utdanning og forsking

Mon Apr 04 2022 10:14:55 GMT+0200 (CEST)
1. Introduksjon
1.1. Bakgrunn
Denne referansearkitekturen er utarbeidet med det som mål at høyere utdanning og forskning skal få en felles datadelingsplattform, digital samhandlingspraksis og informasjonsforvaltningspraksis.
Økt deling av data er en forutsetning for å realisere flere av initiativene i ‘Handlingsplan for digitalisering i høyere utdanning og forskning’ innenfor de funksjonelle områdene utdanning, forskning og administrasjon.
1.1.1. Behov og bruksområder
Referansearkitekturen skal skape samhandling gjennom datadeling, bidra til å støtte bruksområder og dekke tilhørende behov i høyere utdannings- og forskningssektorene.
De viktigste funksjonelle behovene er:
-
Videreutvikle datadeling for læring og forskning
-
Tilrettelegge for fleksibel læring gjennom hele livet
-
Gjøre forskning og forskningsresultater lettere tilgjengelig
-
Muliggjøre brukernær innovasjon
-
Forbedre deling av data mellom administrative tjenester for å støtte administrative prosesser
-
Fremme automatisering av saksbehandling
-
Tilrettelegge for «orden i eget hus» gjennom å bygge opp under felles praksis for informasjonsforvaltning
-
Skape trygge og sikker rammer for datadeling
-
Effektivisere forvaltning av informasjon
Tekniske behov som ønskes løst gjennom bruk av en referansearkitektur:
-
Forbedre evne til endring i IT-systemporteføljen
-
Felles integrasjonspraksis mellom IT-systemer
-
Skape felles kontekst for kravstilling i anskaffelser samt utvikling, drift og forvaltning av integrasjoner
-
Støtte implementasjonen av felles identitets- og tilgangsstyring
-
Tilby en felles begrepskatalog, datakatalog, API-katalog og notifikasjonskatalog med autorisasjon
-
Gi veiledning for definisjon av datakilder, datasett, API og notifikasjoner
-
Definere felles roller for tjenesteforvaltning, dataforvaltning og informasjonsforvaltning
-
Sørge for at høyere utdannings- og forskningssektorene følger de nasjonale og sektorspesifikke retningslinjer som Digitaliseringsdirektoratet og andre spesifiserer
Disse behovene er beskrevet mer detaljert i Vedlegg D Behov og bruksområder som skal dekkes av referansearkitekturen
1.1.2. Gevinst
En felles referansearkitektur legger til rette for at utdanning, forskning og administrasjon kan dekke sine datadelingsbehov på en måte som gir følgende gevinst. Effektiviteten økes når økt oversikt og forbedret samhandling muliggjør fjerning av unødvendige kopier av data og unødvendige varianter av begreper. Disse forbedringer reduserer administrativt byrde. Endringsevne og innovasjon økes når bruksnære kontekster får tilgang til forenklet og tilpasset datasett av høy kvalitet til sitt bruk. En forbedret informasjonsforvaltningspraksis og datadelingsplattform vil gi økt tilgang til data av høy kvalitet, som igjen muliggjør datadrevne beslutninger.
1.1.3. Føringer, pågående og videre arbeid
Referansearkitekturen beskrevet i dette dokumentet tar utgangspunkt i pågående arbeid og førende strategier og prinsipper nasjonalt, innen høyere utdannings- og forskningssektorene og internasjonalt.
Dette er beskrevet i Vedlegg E Føringer, samt "Om våre referansearkitekturer" for videre arbeid.
1.2. Forankring
Referansearkitekturen er utarbeidet i et samarbeidsprosjekt Datadeling med prosjektdeltagelse fra NTNU, Universitetet i Oslo, daværende Unit og Uninett (per januar 2022 HK-dir og Sikt). Styringsgruppen består av medlemmer fra Sikt, Universitetet i Bergen, OsloMet, Universitetet i Oslo, Norges Miljø- og Biovitenskaplige universitet.
1.3. Målgruppe
Målgruppen for referansearkitekturen er primært arkitekter og tekniske prosjektledere. De delene av dokumentet som omhandler informasjonsforvaltning er også relevant for domeneansvarlige, begrepsansvarlige, tjenesteeiere, tjenesteansvarlige, utviklere og datakonsumenter (disse rollene er definert i dette dokumentet).
2. Tilnærming til utvikling av referansearkitekturen
Denne referansearkitekturen skal gi veiledning til utforming av digitale samhandlingsløsninger for deling av data i høyere utdanning og forskning. Denne seksjonen gir veiledning om hva som skal oppnås gjennom en presentasjon av hva datadeling er, en visjon om hva vi skal bruke det til, og modellene som skal skape fundament for utforming av løsningene i visjonen.
2.1. Hva er datadeling
Følgende definisjon for datadeling er hentet fra Digitaliseringsdirektoratets temaområde for datadeling.
Vi tolker definisjonen til å gjelde uansett om data flyttes til konsumenten eller om konsumenten får tilgang til data hvor de ligger. Innen forskning, for eksempel, kan det være hensiktsmessig å gi konsumenter av veldig store datamengder tilgang til å utføre analyse på data der de ligger.
2.2. Et økosystem for datadeling
I arbeidet med denne referansearkitekturen har vi tatt utgangspunkt i en idé om samhandling mellom ulike parter i et større hele. Dette er basert på visjonen om et økosystem, der aktører utfyller hverandre og samhandlingen skaper større verdi enn de enkelte aktører kan klare hver for seg. Studenter, undervisere, forskere og tjenestetilbydere med flere skal både skape, tilby, bearbeide og konsumere data på nye måter som gir alle insentiv og gevinst. I økosystemet for deling av data i høyere utdanning og forskning ser vi for oss de forskjellige aktørene i forskjellig kontekst kalt domener (se seksjonen under). Økosystemet skal etableres opp på en datadelingsplattform, og elementene i plattformen er spesifisert i referansearkitekturen.
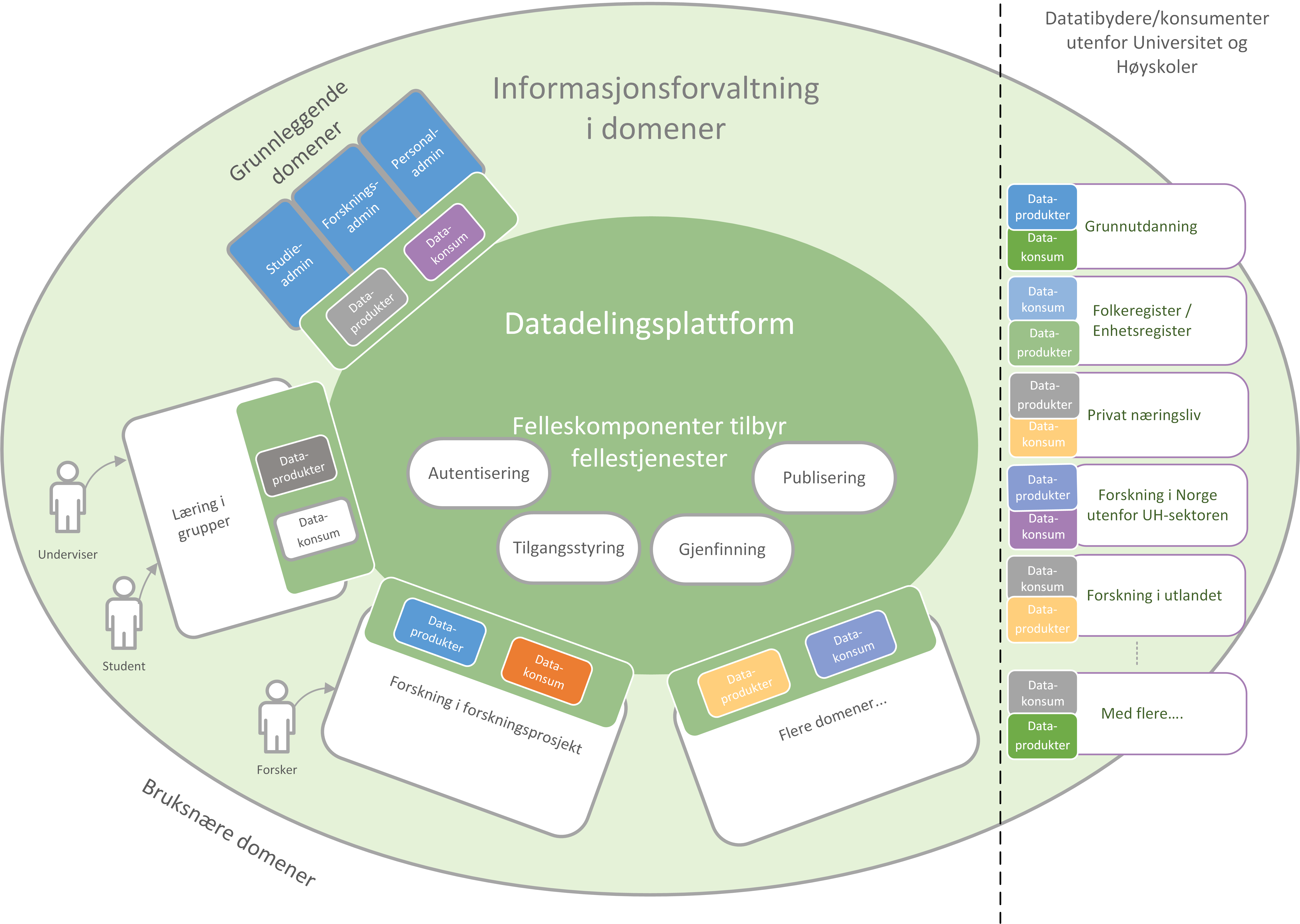
Figuren viser datadeling i og mellom domener. Dataprodukter tilgjengeliggjøres og deles mellom domenene i økosystemet. Domenene kan opptre som datatilbydere (tilbyr dataprodukt) og datakonsumenter (datakonsum). Datadelingsplattformen og fellestjenestene i den muliggjør datadelingen i økosystemet.
2.3. Domener
Informasjonen som skal forvaltes finnes i en faglig kontekst som vi kaller et «domene».
Innen et domene definerer et fagområde sine begreper i det vokabularet som benyttes der. For eksempel vil et begrep som «Søker»[1] ha en beskrivelse, forståelse og sine egne data i et studieadministrativt domene.
Som en del av den generelle utvikling innen IT systemer, er høyere utdannings- og forskningssektorene i ferd med å bygge en distribuert arkitektur som knytter sammen løst koblede, delte datakilder. Referansearkitekturen er laget for å støtte denne utviklingen ved å benytte domener som utgangspunkt for informasjonsforvaltning, utvikling av datakilder, datasett, API og hendelser.
Referansearkitekturen beskriver en datadelingsplattform som støtter deling av data mellom domener gjennom både API og publisering av hendelser. Vi grupperer domenene i grunnleggende domener og domener utviklet for spesielle brukstilfeller som avbildet under.
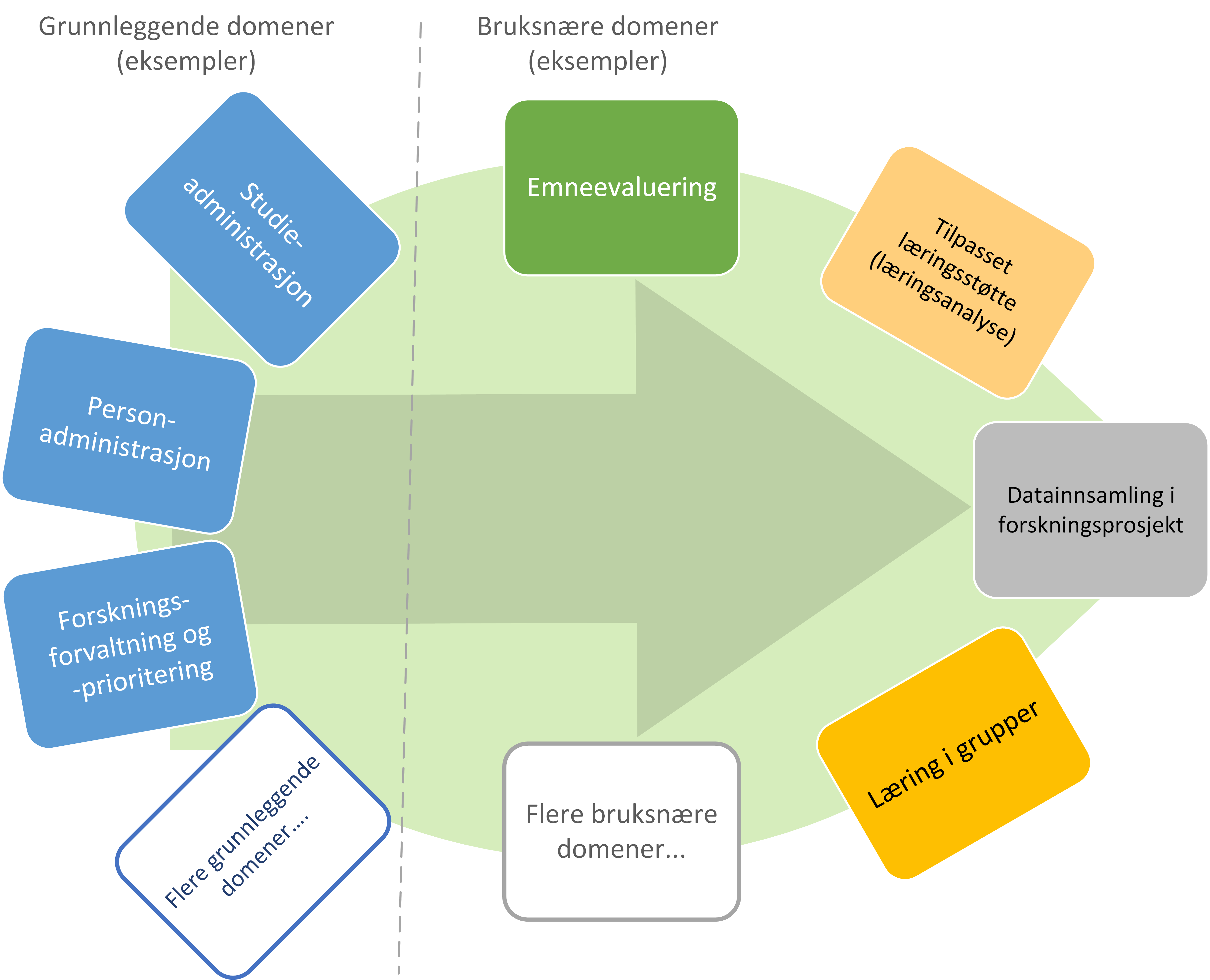
De grunnleggende domenene inneholder kontekst som støtter de sentrale prosessene for læring, forskning og administrasjon hos institusjonene. Denne konteksten vil omfatte begreper, informasjonsmodeller, prosesser og dersom det er hensiktsmessig, også data.
Disse domenene inneholder blant annet masterdatakilder med informasjon om, for eksempel, studenter, ansatte, forskningsprosjekt, forskningsresultater, læringsobjekter, med flere. Den semantiske betydningen av objektene og deres attributter i masterdatakildene skal reflektere en omforent forståelse av disse begrepene. Disse kildene er definert ut fra en dyp forståelse av sektorenes funksjon og vil typisk være forholdsvis stabile over tid.
API og datasett definert i grunnleggende domener blir gjerne gjenbrukt av bruksnære domener.
De bruksnære domenene er definert til å støtte en spesifikk brukskontekst. Domener for brukskontekst inkluderer for eksempel situasjoner der studenter evaluerer emner, der studenter får automatisert tilbakemeldinger for å forbedre læringsprosessen (læringsanalyse) og der deltagere i forskningsprosjekt samler data.
Datasett og API definert her skal være spesifikke og skreddersydd til brukskonteksten.
Vi har hentet denne tilnærmingen fra faglitteratur om Data Mesh[2] av Zhamak Dehghani. Arkitekturen påvirker rutiner for utvikling av API, datasett og notifikasjoner beskrevet i seksjonen Rutiner samt roller og ansvar beskrevet i seksjonen Roller og ansvar for datadeling og informasjonsforvaltning.
2.4. Hva er felles
Domenene beskrevet over, og rollene knyttet til disse får en definert avgrensning. Tilnærmingen til avgrensing følger fra strategiske valg i Handlingsplanen for digitalisering i høyere utdanning og forskning. Disse valg er knyttet til hva som skal være standardisert, hva som skal være felles og hva som skal variere og fremme innovasjon. Administrasjons- og støtteprosesser skal i størst mulig grad benytte standardiserte arbeidsprosesser og felles begreper. Lærings- og forskningsprosesser skal fremme innovasjon gjennom arbeidsprosesser som understøtter faglig autonomitet. [3]
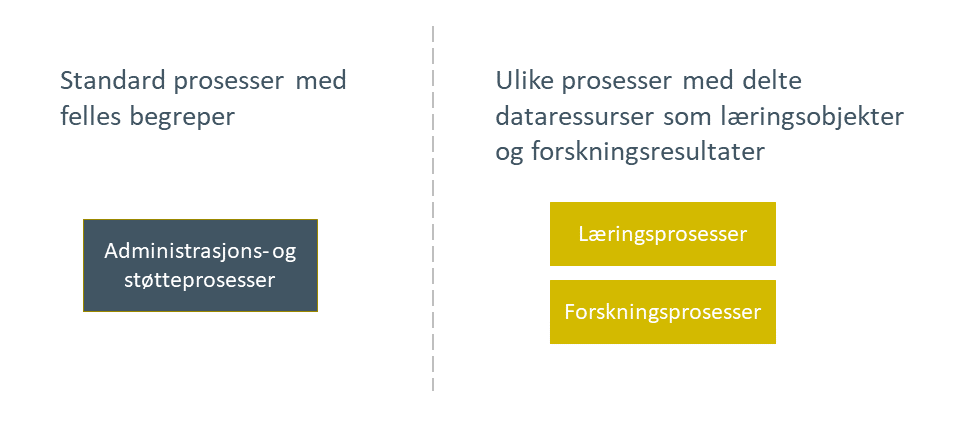
Disse ulike tilnærmingene har ulike behov for deling av data, og vi har benyttet disse føringene i avgrensning av domenene og rollene i referansearkitekturen.
Administrative prosesser og begreper skal være mest mulig standardisert. For å oppnå dette knyttes de til informasjonsdomener som representerer sektorene som helhet der definisjon av prosesser og begreper skal skje. Denne tilnærming er i tråd med eksisterende harmoniseringsprosesser i sektorene. Samtidig er data som inngår i de standardiserte, administrative prosessene hovedsakelig lokale data for den enkelte institusjon hvor prosessen kjøres.
Lærings- og forskningsprosesser vil variere og være knyttet til en brukskontekst med et tilhørende informasjonsdomene. Aktører knyttet til bruksnære lærings- og forskningsdomener vil typisk ønske en bred tilgang til lærings- og forskningsressurser produsert av andre hos institusjonen, nasjonalt og internasjonalt. Det kan også være ønskelig å publisere resultater fra bruksdomer bredt. Brukernære domener innen læring og forskning vil derfor ønske støtte til å dele ressurser på tvers av institusjonene. Eksempler på tjenester som muliggjør slik datadeling er Nasjonalt Vitenarkiv og eventuelle «Learning Object Repositories».
2.5. Samhandling og datadeling
Når datatilbydere og datakonsumenter deler data, skjer det som en del av en digital samhandling. For at samhandlingen skal være vellykket, må tilbydere og konsumenter sikre at de handler i henhold til loven (juridisk samhandlingsevne), at aktørene har avklart forventninger til hverandre og klarer å samarbeide (organisatorisk samhandlingsevne), at datatilbydere og konsumenter har samme forståelse av dataenes betydning (semantisk samhandlingsevne) og at de tekniske løsningene som utfører datadeling fungerer sammen slik de skal (teknisk samhandlingsevne). Rammeverk for digital samhandling vist under utdyper disse samhandlingsevnene.
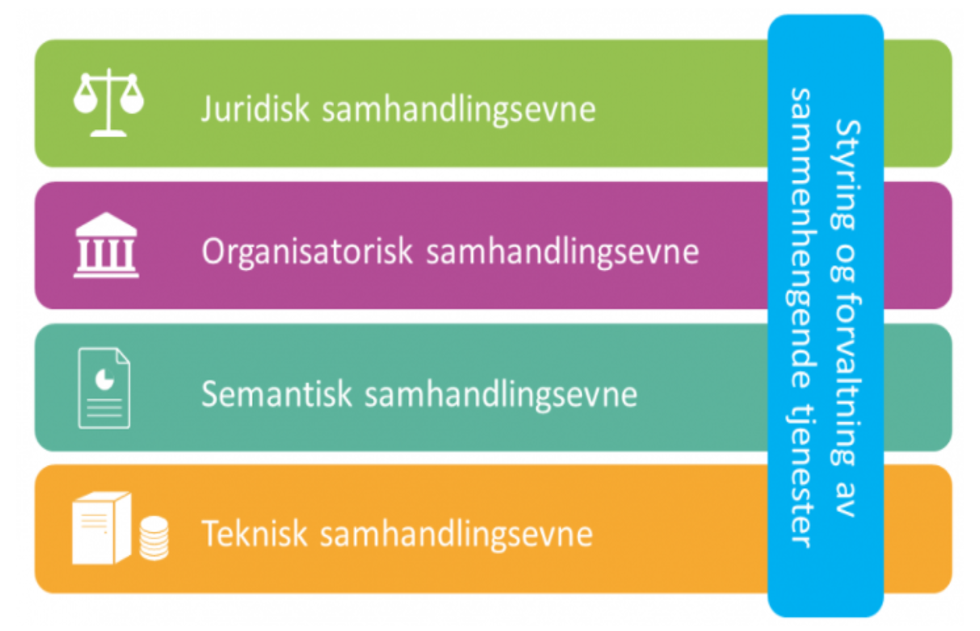
Modellene som er utgangspunkt for referansearkitekturen for deling av data i høyere utdanning og forskning er laget for å ivareta juridisk-, organisatorisk-, semantisk- og teknisk samhandlingsevne og hjelper dermed de som benytter modellene til å lykkes med digital samhandling.
2.6. Verktøykassen for deling av data
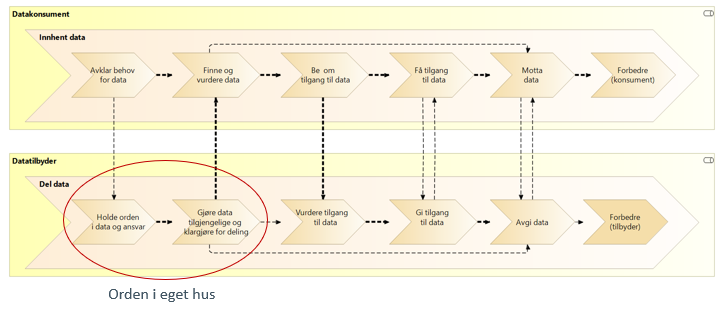
Verktøykasse for deling av data fra Digitaliseringsdirektoratet gir veiledning for de som skal bruke data fra andre (datakonsumenter) og de som skal dele data med andre (datatilbydere). Den overordnede prosessen brukt av datakonsumenter og datatilbydere for å dele data er beskrevet i verktøykassen og avbildet under.
Modellen beskriver verdistrømmer for både de som skal bruke data fra andre (datakonsumenter) og for de som skal dele data med andre (datatilbydere), samt forholdet mellom disse to verdistrømmene.
Verdistrømmene viser hvilke steg en datakonsument må gjennom for å motta data, og hvilke steg en datatilbyder må gjennom for å avgi data. Enkelte steg i verdistrømmene er tilpasset høyere utdannings- og forkninssektorene i referansearkitekturen. Dette er beskrevet senere i dokumentet
Før datatilbyderen kan utføre det første steget i verdistrømmen for datadeling må organisasjonen ha oversikt over egne data som skal deles. For å kunne utføre det andre steget i verdistrømmen må datatilbyderen ha evnen til å publisere datasettene slik at andre kan benytte disse. Disse stegene er sentrale i «orden i eget hus». For at datadeling skal fungere etter hensikten, må dataene også ha god kvalitet. Dette krever kapabiliteter innen informasjonsforvaltning. Vi har modellert disse evner som «muliggjørende kapabiliteter» i referansearkitekturen for høyere utdanning og forskning med utgangspunkt i EUNIS sin kapabilitetsmodell for europeiske universiteter som vist under. EUNIS modellen er utviklet gjennom som et samarbeid mellom europeiske universiteter.
2.7. Muliggjørende kapabiliteter
For å være i stand til å utføre stegene i prosessen over, må organisasjoner opparbeide evner, kalt «kapabiliteter». Noen kapabiliteter er knyttet til bestemte steg i verdistrømmen over. Andre kapabiliteter er generelle og «muliggjørende» for alle steg i verdistrømmen.
God informasjonsforvaltning støtter både opp om organisatorisk samhandlingsevne gjennom å gi organisasjoner riktig data av god kvalitet og støtter opp om semantisk samhandlingsevne ved å klargjøre dataenes betydning.
Vi velger også å synliggjøre juridiske tjenester som muliggjørende kapabilitet for å støtte opp under juridisk samhandlingsevne. Alt i alt krever digital samhandling kapabiliteter som er tverrfaglige, der ingen kan fungere uten de andre.

2.8. Organisering og forvaltning av informasjon i domener for høyskoler, universiteter og forskning
Hvert domene har sin egen informasjon som må forvaltes. Referansearkitekturen foreslår roller som har dette ansvaret i seksjonen Roller og ansvar for informasjonsforvaltning. Informasjonsforvaltning basert på domeneansvar forutsetter at høyere utdannings- og forskningssektorene blir enige om hvilke domener de skal forholde seg til og hvem som skal bekle rollene koblet til dem. Sektorene er allerede i gang med å definere funksjonsområder som kan være utgangspunktet for definisjon av informasjonsdomener. Arbeidet skjer både som analyse av evner (kapabiliteter) som virksomhetene skal ha og som en kartlegging av sektorenes kjernevirksomhet i en «funksjonsanalyse» for saksbehandlings- og arkiveringsformål.
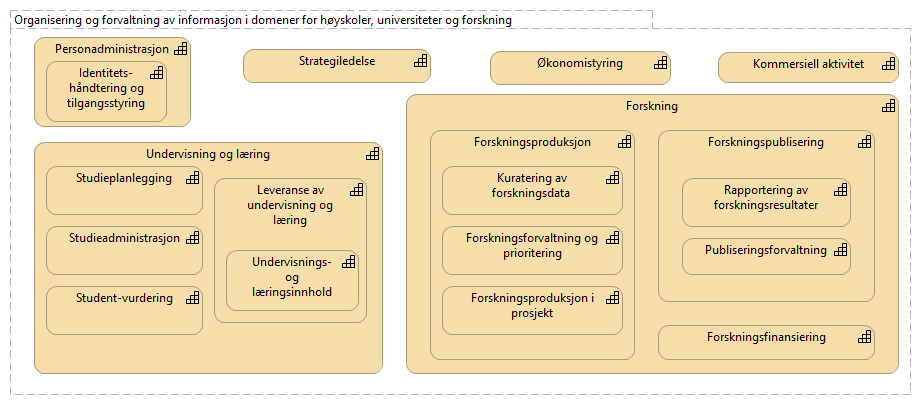
Europeiske universiteter har modellert sine kapabiliteter i EUNIS kapabilitetsmodellen, en modell som nå gradvis migreres inn i HERM fra CAUDIT, støttet av EDUCAUSE og UCISA. Disse modellene er brukt som utgangspunkt for å foreslå noen informasjonsforvaltningsdomener for data som institusjonene ønsker å dele. De foreslåtte domenene er vist i figuren under. Innenfor hver domene har fageksperter eierskap til begrepsdefinisjoner i domenet.
Arbeidet med funksjonsanalyse for arkiveringsformål er en annen kilde til definisjon av informasjonsdomener. NTNUs representasjon av HERM fra CAUDIT med mapping til funksjonsanalysen er tilgjengelig her.
3. Roller og ansvar for informasjonsforvaltning
Digitaliseringsdirektoratet har definert rollene til datatilbydere og datakonsumenter. Foringene beskrevet der peker blant annet til rollen behandlingsansvarlig fra Datatilsynet som gjelder der hvor personopplysninger behandles. Behandlingsansvaret kan følge direkte av lovverket, men må ellers fastlegges ut fra en vurdering av hvilket eller hvilke organ som «alene eller sammen med andre bestemmer formålet med behandlingen av personopplysninger og hvilke midler som skal benyttes», jf. personvernforordningen art. 4 nr.7. Forventning til datatilbydere og datakonsumenter er også beskrevet i Nasjonal verktøykasse for deling av data. Vi anbefaler at disse veiledere brukes, samtidig som vi definerer mer fingranulerte roller.
Rollene spesifisert under er for både datatilbydere i IT-tjenesteorganisasjoner og for informasjonsforvaltning i domenene de støtter.
Vi hadde ønsket å definere rollen «dataeier» men opplevde juridisk uklarhet i dataeierskap, særlig når det gjaldt data om studenter i en livslang læringskontekst. Denne rollen må derfor defineres senere. Følgende roller er definert under.
Roller hos datatilbydere:
-
Tjenesteeier
-
Tjenesteansvarlig
-
Dataforvalter
Roller relatert til informasjonsdomener:
-
Domeneansvarlig
-
Begrepsansvarlig
Koordinerende aktør for hele Kunnskapsdepartementets sektor (HK-dir)
3.1. Tjenesteeier
| Rolle: | Tjenesteeier |
|---|---|
Beskrivelse av rollen: |
Tjenesteeier er den organisasjon/virksomhet/enhet som eier en tjeneste. Ansvarsområdene til tjenesteeier vil tillegges en leder som påser at tjenesteansvar og dataforvaltning utføres i henhold til brukernes behov og brukskontekstens krav til utforming, sikkerhet og kvalitet. |
Ansvars-områder og oppgaver: |
Er ansvarlig for at tjenestens data/masterdata deles iht. Referansearkitektur (dvs. generiske grensesnitt og notifikasjoner, eksempel IntArk). Er ansvarlig for at tjenestenivå (fullstendig sett av krav til tjenesten med tilhørende beskrivelser: eks. tilgjengelighet, omfang, volum, hyppighet, varighet, rapportering) er definert i henhold til brukeres behov, at det inneholder kvalitetssikret faglig innhold og at brukerne får faglig støtte. Er ansvarlig for at tjenesten følger gjeldende lover og regler, har myndighet til å foreta finansielle beslutninger og signere avtaler. Er ansvarlig for at det er utpekt en tjenesteansvarlig for tjenesten og en dataforvalter for data i den. |
Typiske roller/stillinger som rollen skal samarbeide med: |
Tjenesteansvarlig, dataforvalter, domeneansvarlig |
3.2. Tjenesteansvarlig
| Rolle: | Tjenesteansvarlig |
|---|---|
Beskrivelse av rollen: |
Rollen har et helhetlig ansvar for å hente inn og bidra til prioritering av ønsker og behov som en kunde eller konsortium har til tjenesten. Tjenesteansvarlig er operativt ansvarlig og har detaljert kunnskap om behov og praktisk bruk av tjenesten. Han/hun jobber i tett samarbeid med brukere/brukerrepresentanter. Tjenesteansvarlig og tjenesteeier kan være samme person for mindre/enklere tjenester. |
Ansvars-områder og oppgaver: |
Budsjett- og resultatansvar i forvaltning og utvikling av tjenesten
Koordinere beslutningsprosess for tjenesten
Brukermedvirkning i utvikling og forvaltning av tjenesten
Kundeoversikt, kundeoppfølging og avtaleforvaltning
Kvalitet og sikkerhet
Tjenesteansvarlig omfatter Databehandlerollen som beskrevet hos Datatilsynet. Denne rollen har ansvar for behandling av personopplysninger på vegne av den behandlingsansvarlige. |
Typiske roller/stillinger som rollen skal samarbeide med: |
Tjenesteeier, Datakonsument, Begrepsansvarlig, Domeneansvarlig, Dataforvalter. |
3.3. Dataforvalter
| Rolle: | Dataforvalter |
|---|---|
Beskrivelse av rollen: |
Den som har overordnet ansvar hos en datatilbyder for å administrere informasjon/data som skal deles (evt. kan ansvaret/rollen fordeles videre og knyttes til, for eksempel, et domene innenfor datatilbyder sin organisasjon). |
Ansvars-områder og oppgaver: |
Leveranse og forvalting av data. Datakvalitet, sikkerhet, tilgjengelighet (inkl. lisensiering hvor det er hensiktsmessig) Motta, registrere, endre og fjerne forekomster. Sikre at bruk av data som eies av tredjepart samsvarer med vilkårene som gis. Overholde krav i arkivloven når det gjelder kassasjon. Rådgivning og bistand i spørsmål vedrørende bruk av data (som angår begrepsdefinisjoner og juridiske føringer). Kommunikasjon med alle interessenter Oppgaver:
|
Typiske roller/stillinger som rollen skal samarbeide med: |
Begrepansansvarlig, Domeneansvarlig, Behandlingsansvarlig, Tjenesteansvarlig |
3.4. Domeneansvarlig
| Rolle: | Domeneansvarlig |
|---|---|
Beskrivelse av rollen: |
Har ansvar for aktiviteter og tiltak innen domenet for å sikre både at begreper og informasjonsmodeller er definert i domenet og for riktig kvalitet, utnytting og sikring av informasjon i domenet. |
Ansvars-områder og oppgaver: |
Være prosessdriver for informasjonsforvaltning Følge med at begrepene blir utarbeidet etter retningslinjer i domenet. Passe på at forvaltningsprosessen blir fulgt og at begrepene har riktig status i forhold til begrepsforvaltningsprosessen. Ha oversikt over helheten og bidra til koordinering, harmonisering og godkjenning av innhold, inklusiv samordning av konsumenter med sammenfallende behov og eksisterende begreper i begrepskatalogen. Publisering av begreper i felles begrepskatalog (data.norge.no) Drive opplæring knyttet til forvaltning av informasjon i domenet. |
Typiske roller/stillinger som rollen skal samarbeide med: |
Begrepsansvarlig, Datakonsument, Tjenesteansvarlig |
3.5. Begrepsansvarlig
| Rolle: | Begrepsansvarlig |
|---|---|
Beskrivelse av rollen: |
Rollen som har det faglige ansvaret for et begreps innhold. |
Ansvars-områder og oppgaver: |
Sørge for at begrepene blir definert i henhold til retningslinjene i rammeverket. Involvere eventuelle interessenter i definisjonsarbeidet Sørge for at begrepene er vurdert i henhold til eksisterende begrepsdefinisjoner i domenet og i felles begrepskatalogen (data.norge.no). |
Typiske roller/stillinger som rollen skal samarbeide med: |
Dataforvalter, Datakonsument, Domeneansvarlig, Tjenesteansvarlig |
3.6. Koordinerende aktør
| Rolle: | Koordinerende aktør |
|---|---|
Beskrivelse av rollen: |
Koordinerende aktør vil opptre på vegne av Kunnskapsdepartmentet (KD) og vil være ansvarlig for å etablere og forvalte KUDAFs datadelingsplattform. Videre skal koordinerende aktør støtte aktørene i å ta i bruk datadelingsplattformen og sikre et godt samarbeid om økosystemet for data i kunnskapssektoren. Sist, men ikke minst skal koordinerende aktør stimulere arbeidet med Orden i eget hus i sektoren. |
Ansvars-områder og oppgaver: |
Prosessarbeid
Tjenesteansvar
Etablere et rådgivende forum for juridiske avklaringer knyttet til deling og utlevering av data |
Typiske roller/stillinger som rollen skal samarbeide med: |
Domeneansvarlig, Begrepsansvarlig, Dataforvalter, Tjenesteeier og Tjenesteansvarlig |
4. Datadelingsplattformen og fellestjenestene i den
Datadeling i og mellom domener i økosystemet skjer ved bruk av datadelingsplattformen i høyere utdanning og forskning. Plattformen skal støtte enkel publisering av data og effektive mekanismer for gjenfinning og tilgang til data for konsumenter som har rett til slik tilgang. Datadelingsplattformen lagrer kun metadata og fungerer som en databroker. Datasettene referert til gjennom metadata lagres og forvaltes hos datatilbyderne. Deling av data i domenene skjer mellom datatilbydere og datakonsumenter eksempelvis innen administrasjon, læringsgrupper, forskningsprosjekt og i samhandling med andre sektorer og næringsliv. Alle kan være datatilbydere og/eller datakonsumenter. Plattformen realiserer prosessene som sikrer at alle kan finne datasett og at tilgang til data er begrenset til konsumenter som skal ha tilgang.
Datadelingplattformen består av felleskomponenter som tilbyr fellestjenester for publisering, gjenfinning og formidling av tilgang. Disse tjenestene er brukt for å realisere datautvekslingsmønstrene beskrevet i referansearkitekturen.
Referansearkitekturen spesifiserer hvordan datasett, API og notifikasjoner skal:
-
defineres
-
brukes
-
gjenbrukes av nye konsumenter
-
brukes til nye oppgaver
-
forvaltes
Data skal forvaltes i autoritative kilde der ansvar er definert. Datasett til nye formål kan være satt sammen av data fra flere andre API. Datadelingsplattformen skal inngå i Kunnskapsdepartementets datafellesskap der det skal bygges et økosystem for bruk av data rundt plattformen.
Virksomhetene i høyere utdanning og forskning må etablere tillit til hverandre for å kunne dele data. Datadelingsplattformen realiserer tilgangsstyring til sektorenes data på en enhetlig måte gjennom bruk av fellestjenester tilbudt i plattformen i felles datadelingsprosesser beskrevet i referansearkitekturen. Hovedmetoden for tilgangsstyring i plattformen er API Management.
Referansearkitekturen definerer hvordan det varsles om endringer i datasett gjennom notifikasjoner. Varslene brukes til å reagere på endringene i datasettet, uten at hele datasettet konsumeres. Muligheten til å reagere på varsler om endringer tilrettelegger for hurtig behandling av data i situasjoner der tidsbruk er et sentralt kriterium for bruksmønsteret.
4.1. Føderert API management
Føderert API Management innebærer at et domene kan gi brukere i andre domener som man har et tillitsforhold til, ofte kalt fødereringspartnere, tilgang til sine egne data gjennom API. Det er flere grunner for å gjøre dette. Mange virksomheter har i dag sine virksomhetsdata lagret distribuert, fordelt mellom systemer som kjører på lokale servere («on-premise») og i skybaserte-løsninger.
Det er et sterkt politisk ønske om deling av data mellom domener. Flere initiativer, slik som Digitaliseringsdirektoratets "Orden i eget hus" og andre nasjonale og sektorvise digitaliseringsstrategier skal understøtte deling av data. I en slik sammenheng ser vi behovet for et felles dataforvaltnings, masterdata og API Management-regime i høyere utdannings- og forskningssektorene.
Et slikt regime muliggjør deling av data for å oppnå sammenhengende brukerreiser, eksemplifisert ved de syv livshendelser og tjenestekjeder. Det er en forutsetning at data kan deles mellom virksomheter som betjener slike brukerreiser.
3.parts aktører kan bruke data fra høyere utdannings- og forskningssektorene for innovasjon. Dataforvaltning og API management kan medvirke til deling av data til 3. part ved å gjøre data gjenfinnbart, tilgjengelig og dokumentert.
Virksomheter i høyere utdanning og forskning har mange fellestrekk og noen fellestjenester på tvers. Deres autonomi gjør likevel at de er ulike på enkelte områder, for eksempel når det gjelder teknisk infrastruktur. Disse likhetene og forskjellene understreker behovet for en føderert API Management-løsning. En slik løsning er mer fleksibel med tanke på tekniske løsninger og produktvalg lokalt.
Felleskomponentene relatert til API-management i referansearkitekturen (se under) er laget for å støtte følgende karakteristikk:
-
Institusjonene er sikret råderett over egne data gjennom tilgangstjeneste i ressursportalen og API gateway hos institusjonen som kan styre og holde oversikt over datatilgang
-
Institusjonene har valgfrihet for API Gateway så lenge funksjoner og grensesnitt er ivaretatt
-
Deling av data på tvers av institusjoner er støttet gjennom felles ressursportal
4.2. Publisering av hendelser
For publisering av hendelser er det etablert et mønster der datatilbyder tilbyr lettvektsnotifikasjoner om hendelser som medfører endringer i datagrunnslaget som datakonsumenten kan abonnere på. Lettvektsnotifikasjonen inneholder en identifikator som peker til hvilke data som er relatert til notifikasjonen. Dette mønsteret er allerede i bruk i høyere utdannings- og forskningssektorene.
Lettvektsnotifikasjonen i en eNotifikasjon blir overført mellom datatilbyder og konsument av en meldingsformidler (message broker). Meldingsformidleren tar imot notifikasjoner om hendelser fra produsenter, og overfører notifikasjonene til de konsumenter som abonnerer på hendelsestypen, samtidig som den sørger for at eventuell leveransegaranti overholdes.
I likhet med behovet for en API katalog som beskriver hvilke APIer som finnes, er det nødvendig med en notifikasjonskatalog som gir et overblikk over hvilke datatilbydere som publiserer notifikasjoner om endring i datagrunnlag.
4.3. Felleskomponenter tilbyr fellestjenester
Datadelingsplattformen består av felleskomponentene beskrevet under. Disse komponentene tilbyr fellestjenestene benyttet i datadelingsprosessene som detaljeres i neste kapittel. De fleste felleskomponenter skal realiseres med en delt instans for høyere utdannings- og forskningssektorene. API gateway er en funksjonell beskrivelse av en komponent som skal realiseres med instanser nær datakildene som skal beskyttes.
4.4. Datadeling integrert med IAM
Infrastruktur for identitetshåndtering og tilgangsstyring (IAM) utfyller API management og notifikasjoner og må fungere sammen.
Autentisering er det som sjekker at brukeren er kjent for virksomheten og forsikrer at brukeren er den vedkommende gir seg ut for å være når brukeren ber om tilgang til ressurser.
Autorisering identifiserer hvilke tilganger en bruker skal ha til virksomhetens ressurser. Autorisasjon kan tildeles med basis i roller. Brukere kan tildeles roller og gjennom dette få autorisasjon til virksomhetens ressurser som er knyttet til rollen. Det kan skilles på disse to måtene å få tilgang på delte data:
-
Systemtilgang
Brukeren har implisitt tilgang gjennom tilgang til konsumenten sitt system i domenet. Konsumentens system har tilgang til API hos tilbyder. Det er konsumenten som må sikre at brukeren har rettighet til å få tilgang til tilbyders data -
Brukersentrisk datadeling
Brukeren må ha eksplisitt tilgang til tilbyder sine delte data i tilbyders system i domenet. Her er det tilbyder som har kontroll over brukerens tilgang på data og kan spore brukerens bruk av disse
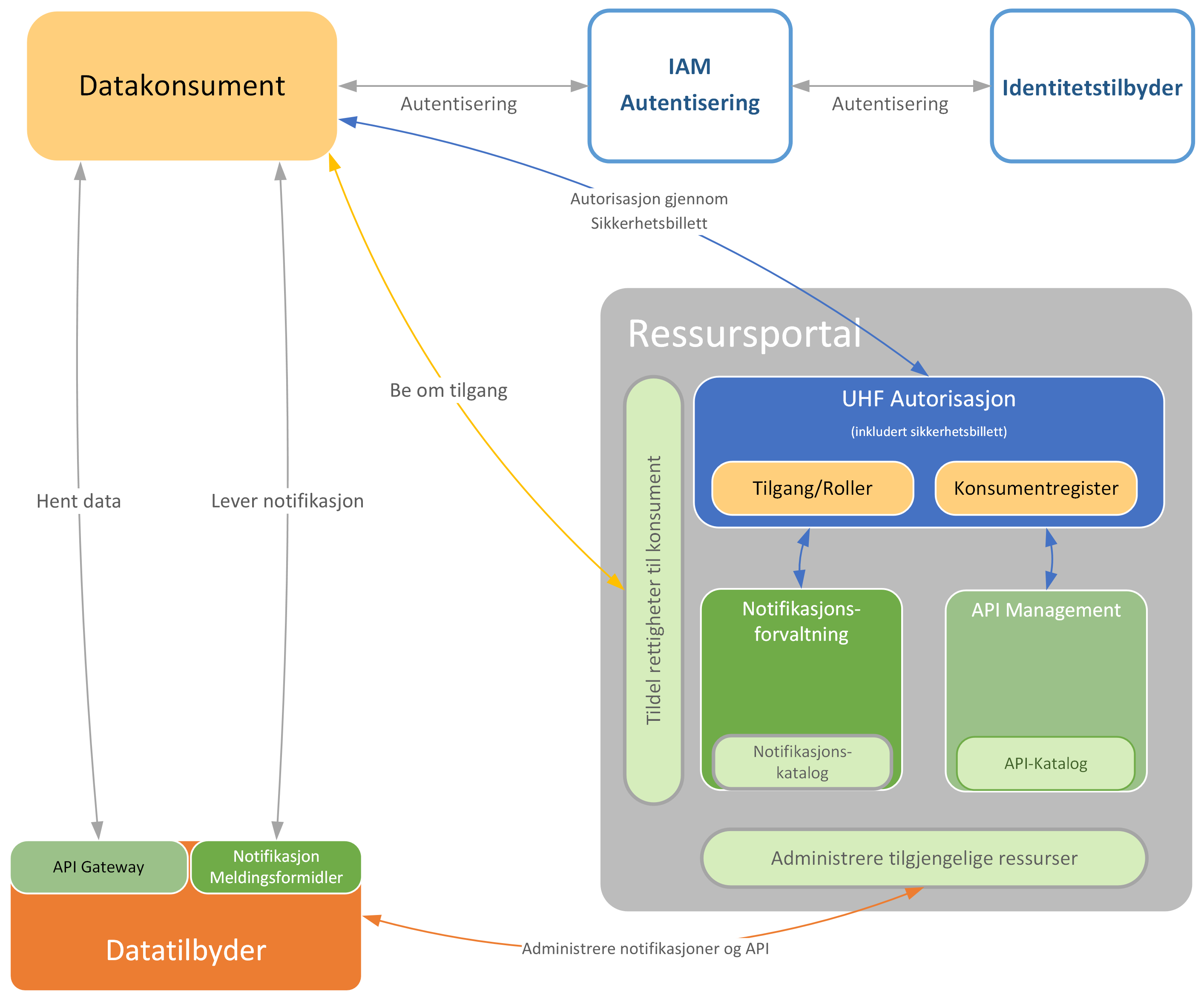
IAM utfører autentisering ved bruk av en autentiseringstjeneste og en identitetstilbyder, som vist i figuren under.
IAM autoriserer sluttbrukeres tilgang til tjenester. Dette er basert på både autentisering av deres identitet, det vil si hvem brukeren er, og de roller brukeren er tildelt hos en eller flere institusjoner.
API management styrer tilgang til data gjennom API basert på policy eller godkjenning fra dataforvalter. Brukers tilgang til beskyttet tjeneste hos datakonsument kan være tilstrekkelig til at bruker ikke trenger å autoriseres eksplisitt hos datatilbyder. Avgjørelsen om å godkjenne tilgang til data kan være basert på en sluttbrukers rolle hos en institusjon.
I UHF autorisasjon inngår autorisering og tildeling av en sikkerhetsbillett (token) ved bruk av en autorisasjonstjener og en token-tjeneste. Denne sikkerhetsbilletten brukes for å få tilgang til API eller notifikasjon hos datatilbyder.
UHF Autorisasjon er en tjeneste som samordner tildeling av sikkerhetsbilletter til datakonsumenter. Sikkerhetsbilletten gir tilgang til en ressurs hos datatilbyderen for en autentisert datakonsument. Tjenesten samordner autorisasjon gjennom verifisering av konsument i konsumentregisteret og sjekk av konsumentens roller og tilganger til API eller notifikasjon.
Ressursportalen og tjenesten for tildeling av rettigheter til datakonsumenter deltar i begge funksjoner.
4.5. Datadeling på tvers av sektorer
Det er behov for datadeling og API Management på tvers av offentlig sektoren og mot privat næringsliv. Høyere utdanning og forskning ønsker utstrakt bruk av nasjonale felleskomponenter, som omtalt i Digitaliseringsrundskrivet og vist i figuren under. For å oppnå dette må både høyere utdannings- og forskningssektorene og den nasjonale infrastrukturen videreutvikles.
Føderert tilgangsstyring for datadeling på tvers av sektorer er ønskelig, og det krever blant annet standardisering av sikkerhetsbilletter (tokens) for å oppnå gjennomgående tillitskjeder. Det er også ønskelig at brukere kan styre samtykke til sine data fra et sted nasjonalt, inklusivt til data i kilder i høyere utdanning og forskning. Det hadde vært ønskelig om en felles Norsk samtykketjeneste kunne være integrert med funksjonalitet som vi forventer skal realiseres i IAM løsningen til høyere utdanning og forskning. Samtykke til kilder i sektorene våre fra Altinn autorisasjon er en mulig fremtidig løsning.
Det er planlagt automatisert høsting av API katalogen fra høyere utdanning og forskning til Felles API-katalog som visst i figuren under.
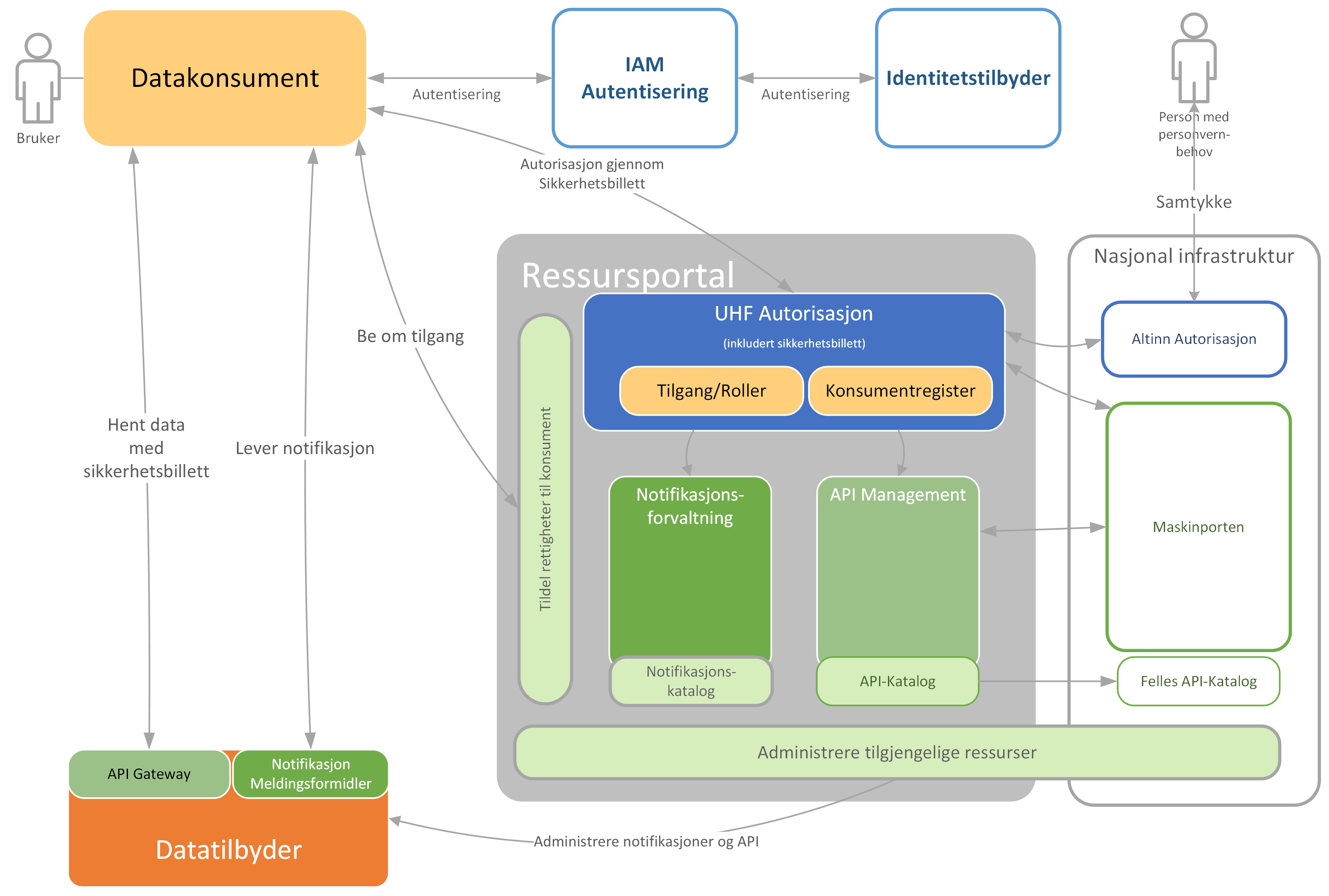
5. Datautveksling
Fellestjenestene i datadelingsplattformen brukes i felles prosesser for å dele data. Gjennom å utføre en fellesprosess, vil en datakonsument eller en datatilbyder oppnå en evne (kapabilitet). Dette kapittelet beskriver de fellesprosessene som er definert for deling av data, og de evnene som oppnås ved å benytte dem. Prosessbeskrivelsen viser hvilke tjenester støtter prosessen, og hvilke komponenter realiserer tjenestene. Prosessbeskrivelsen viser også de sentrale forretningsobjekter og dataobjekter som benyttes og produseres underveis. Både tjenester og komponenter kan aksessere dataobjekter.
Prosessbeskrivelsene er presentert i ArchiMate modelleringsspråk. Vår bruk av Archimate er beskrevet i Vedlegg F. Prosesstegningene er definert for høyere utdanning og forskning, omtalt som "UHF".
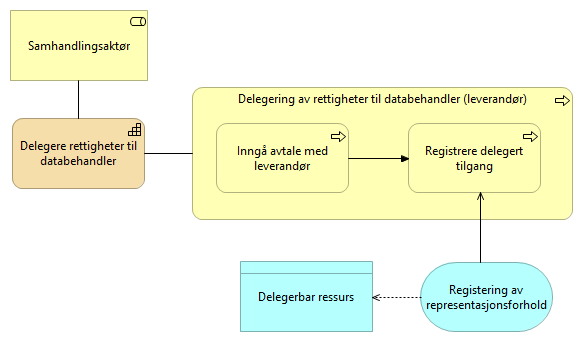
5.1. Delegere rettigheter til databehandler - UHF
Delegering av rettigheter til databehandler er det en konsument må gjøre for at en leverandør kan identifisere seg med sitt eget virksomhetssertifikat og opptre på vegne av konsumenten som er den som innehar behandlingsgrunnlaget for å innhente data.
5.2. Datautveksling ved oppslag
5.2.1. Datautvekslingsmønster
Synkront oppslag
Synkront oppslag er realiseringen av eOppslag. I dette mønsteret hentes data fra datakilden ved behov. Et typisk eksempel på synkront oppslag kan være uthenting av aktuelle konteringsregler fra økonomisystemet ved prevalidering av regnskap før det føres i hovedbok.
Provisjonering via synkront oppslag
Synkront oppslag kan også benyttes til provisjonering. I et slikt tilfelle hentes all informasjon det er nødvendig å lagre i et system fra datakilden. Ved provisjonering med synkront oppslag er det ofte store mengder data i bevegelse, og overføringen tar tid. Disse egenskapene medfører at provisjonering via synkront oppslag utføres sjelden. Denne metoden blir ofte kalt batch-provisjonering.
Provisjonering via lettvekts eNotifikasjoner
I de tilfellene provisjonering via synkrone oppslag ikke kan besørge en propageringshastighet som understøtter brukernes behov, kan lette eNotifikasjoner benyttes i kombinasjon med eOppslag. De lette eNotifikasjonene bærer informasjon om hvilke data som har endret seg i datakilden, og leveres umiddelbart til de som måtte være interessert i dataendringene. Dette tillater systemet som er avhengig av provisjonering å hente kun den informasjonen som har blitt endret.
Et typisk eksempel på bruk av dette mønsteret er en professor som publiserer en artikkel i Nasjonalt Vitenarkiv. Professorens personprofil på institusjonens nettsider blir oppdatert snarlig etter at artikkelen er publisert i Nasjonalt Vitenarkiv, siden det blir sendt en lettvekts notifikasjon om registreringen.
Fremtidige utvidelser
Digitaliseringsdirektoratets referansearkitektur definerer to varianter av eNotifikasjon, den tidligere omtalte lettvektsvarianten, og en basert på hendelseslister.
Hendelseslister består av notifikasjoner som konsumeres via eOppslag. Notifikasjonene kan inneholde varierende mengde informasjon, og propageres ikke like hurtig som lettvektsvarianten beskrevet ovenfor. Hendelseslistene er persistente av natur (til forskjell fra lettvektsvarianten, der notifikasjonene «forsvinner» når de er konsumert), og lar sådan datakilden beskrive en historikk. Et typisk eksempel på en slik historikk kan være de forskjellige stegene i en saksbehandlingsprosess, der de forskjellige stegene må være klart definert for å kunne foreta videre steg i saksbehandlingsprosessen, eller realisere etterlevelse av juridiske krav.
I neste versjon av referansearkitekturen vil det vurderes å inkludere varianten basert på hendelseslister. Det vil også vurderes å utvide definisjonen av lettvektsnotifikasjoner slik at de kan bære konkrete data (også kalt Event Carried State Transfer), til forskjell fra eksisterende definisjon der de kun bærer en referanse til dataene som er endret.
5.2.2. eOppslag Verdistrøm med kapabiliteter for tilbyder og konsument - UHF
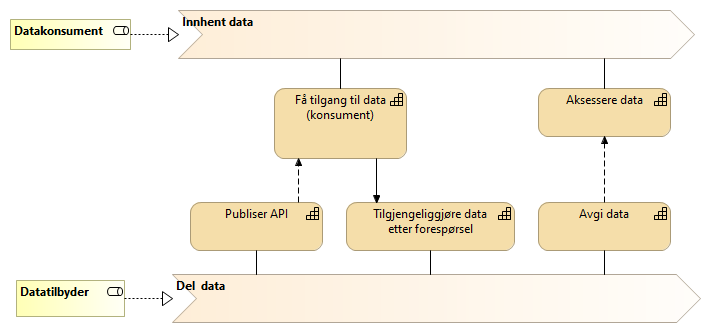
5.2.3. Publiser API
En prosessflyt som datatilbyder må gjennomføre for å gjøre et API synlig og tilgjengelig gjennom kataloger og søkeløsninger. Metadata om APIet blir registrert i API-katalogen. Metadata inkluderer begreper og datamodeller omfattet av datasettet som APIet tilgjengeliggjør, samt tilganger (scopes) knyttet til APIet som kan tildeles konsumenter.
APIet registrert i UHF API katalog blir høstet inn i Felles API katalog. Vi ønsker at tilganger (scopes) i tillegg skal registreres i Maskinporten slik at konsumenter utenfor UHF sektoren kan oppdage APIet og be om tilgang på et senere tidspunkt.
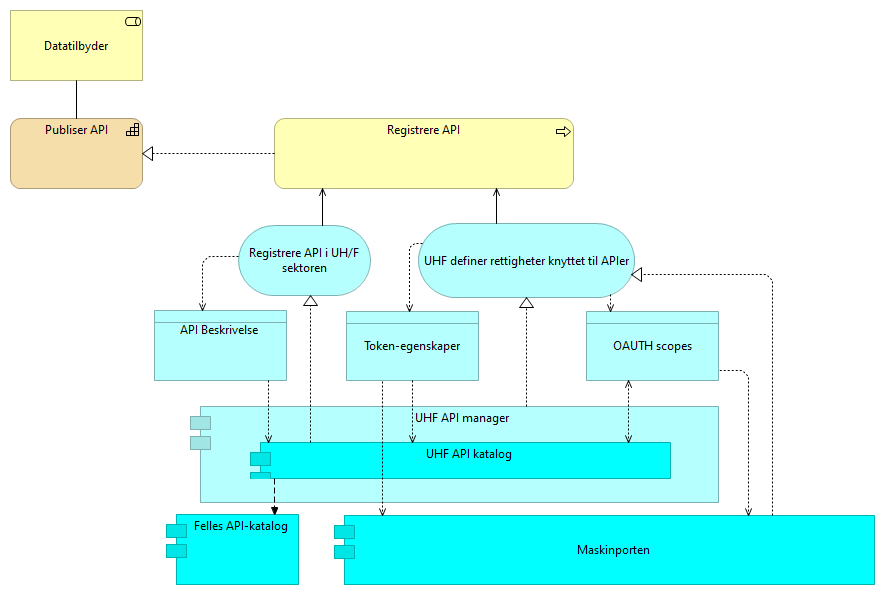
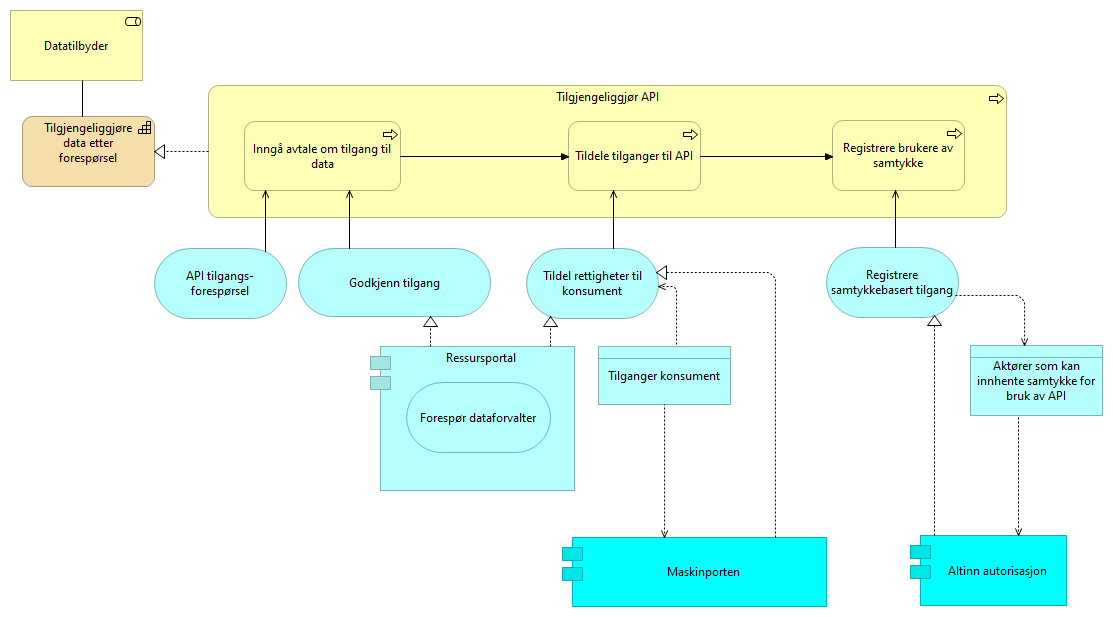
5.2.4. Tilgjengeliggjøre data etter forespørsel - løsningsmønster UHF
En prosessflyt som datatilbyder må gjennomføre for å tildele rettigheter til en konsument som ber om tilgang til data. En datatilbyder mottar forespørsel om tilgang til et API på vegne av en organisasjon eller bruker. Dataeieren tar stilling til om konsumenten skal få tilgang til data gjennom APIet. Tilgang registreres knyttet til konsumentens klient (applikasjonen som benytter APIet) i klientregisteret.
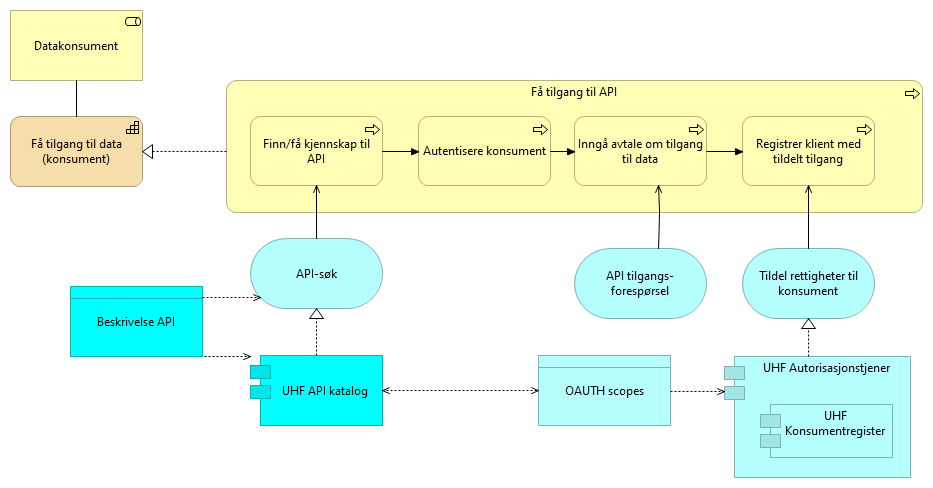
5.2.5. Få tilgang til data - løsningsmønster UHF
En prosessflyt en konsument av data må gjennomføre for å få tildelt rettigheter til data gjennom et API. Det omfatter å få kjennskap til aktuelt API gjennom API-katalogen, autentisere konsumenten, inngå avtale om bruk av data, samt å registrere tilganger hos den tekniske komponenten som skal utføre tjenestekallet. Dersom det dreier seg om tilgang til et åpent tilgjengelig API, kan enkelte delaktiviteter i prosessene hoppes over, men for å kunne logge informasjon om bruk av APIer bør alle konsumenter av et API registreres i klientregisteret.
Viewet bør strengt tatt vise at konsumenten kan finne APIet enten i UHF sektorens API katalog eller i Felles datakatalog. Vi velger å vise prosessflyten kun med UHF sektorens komponenter både for å kunne presentere en oversiktlig prosessflyt og fordi forholdet til de nasjonale felleskomponenter ennå ikke er helt avklart.
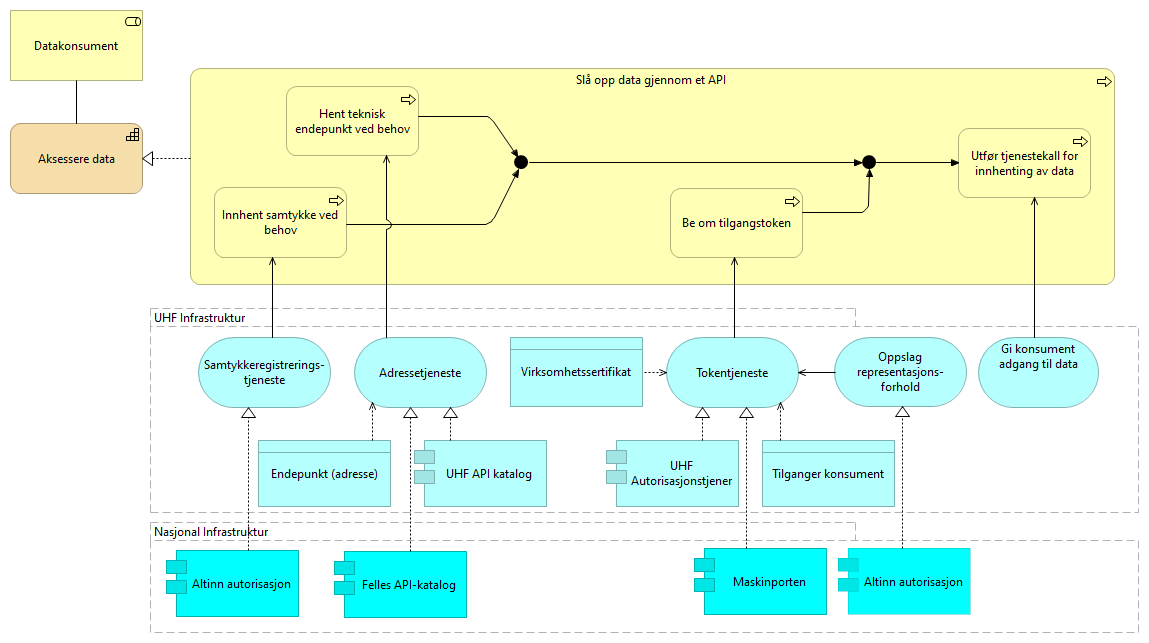
5.2.6. Innhente data - løsningsmønster UHF
En prosessflyt en konsument utfører når det utføres et tjenestekall for å innhente data gjennom et API. API-adressen hentes i API-katalogen. Tilgang til APIet byttes inn mot et kjøretids-token i autoriseringstjenesten. Tjenestekall til APIet utføres gjennom API gateway der tokenet benyttes for å få tilgang. Dersom det er et åpent API er det kun relevante prossessteg som utføres.
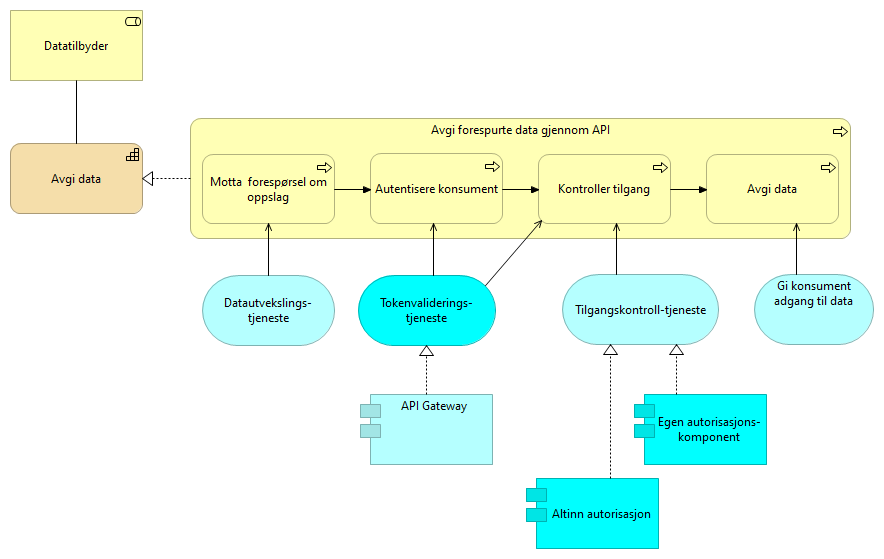
5.2.7. Avgi data - løsningsmønster UHF
En prosessflyt en tilbyder av data utfører for å svare på en dataforespørsel. Tilbyder mottar forespørsel om oppslag med et aksesstoken. Klienten som forespør autentiseres og token valideres. Eventuelt mer fin-granulert tilgangskontroll utføres og data returneres. Tilgang kontrolleres kun dersom det er snakk om et sikret API.
5.3. Datautveksling ved publisering – konsumering (hendelsesbasert)
Datautveksling ved publisering og konsumering av hendelser er basert på publisering-konsumering i Referansearkitektur for datautveksling fra Digitaliseringsdirektoratet.
5.3.1. Publisering av hendelser - basiskonsept UHF
Hendelser er endringer som oppstår hos en datatilbyder og som nødvendiggjør at datatilbyder deler denne endringen med andre.
Datatilbyder publiserer en hendelse til en hendelsesstrøm. Datakonsument konsumerer hendelser fra hendelsesstrømmen og om nødvendig gjør oppdateringer av sine data.
Hendelsestrømmer implementeres som lettvekts notifikasjoner i en notifikasjonskø (publiser/abonner).
Alternative måter er blant annet hendelseslister, som beskrevet i Digitaliseringsdirektoratets referansearkitektur for datadeling og i kapittelet Datautvekslingsmønster.

5.3.2. eNotifikasjon - oversikt over verdistrømmer UHF
Den overordnede verdistrømmen vist under skisserer handlingene hos datatilbyder og datakonsument som inngår i dette utvekslingsmønsteret. Datatilbyderen oppretter en hendelsesstrøm som datakonsumenten oppdager og abonnerer på. Datatilbyderen publiserer notifikasjoner om hendelser i hendelsesstrømmen, og datakonsumenten innhenter disse. Når konsumenten har mottatt en notifikasjon, vurderer konsumenten om det er behov for å innhente mer informasjon om hendelsen. I så fall benytter konsumenten synkront oppslag som beskrevet tidligere for innhentingen.
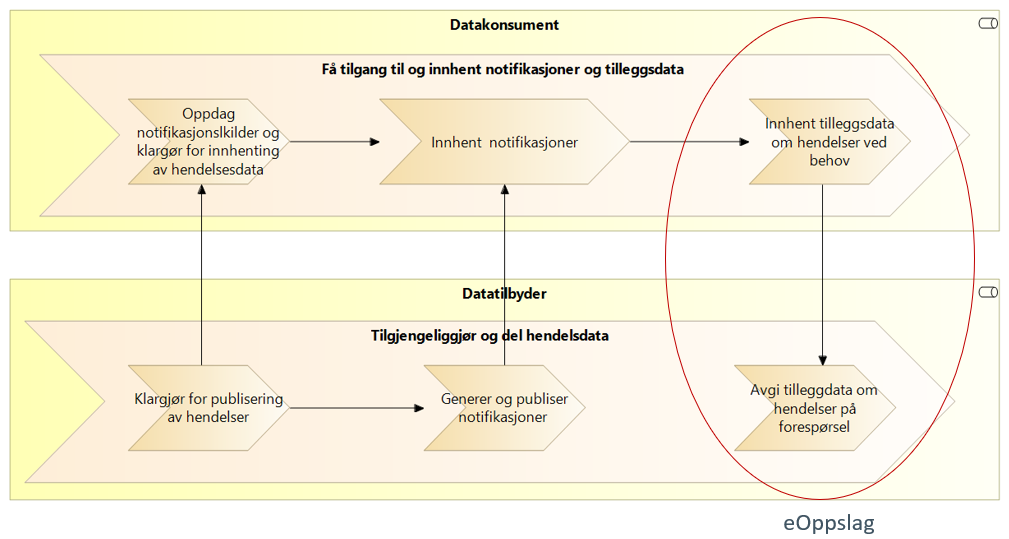
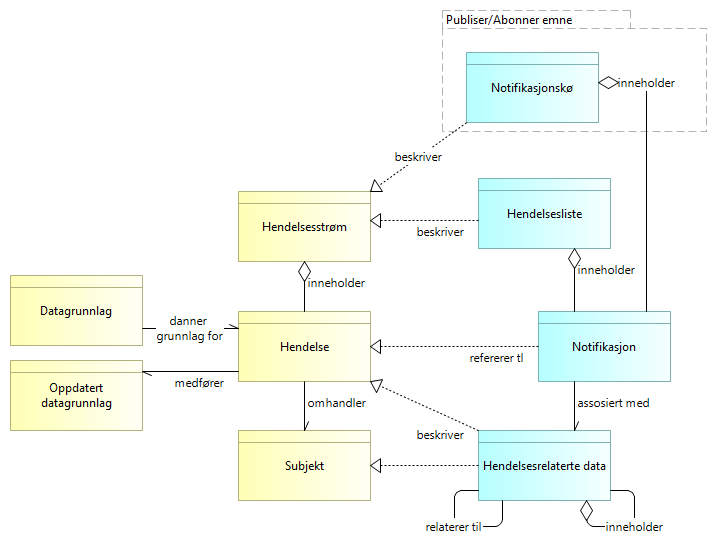
5.3.3. Grunnleggende begreper for publisering av hendelser - Hendelsesliste, Publiser og Abonner UHF
Notifikasjoner blir publisert i form av publisering/abonnering til en notifikasjonskø. Hendelseslister er en alternativ måte å beskrive en slik strøm av hendelser.
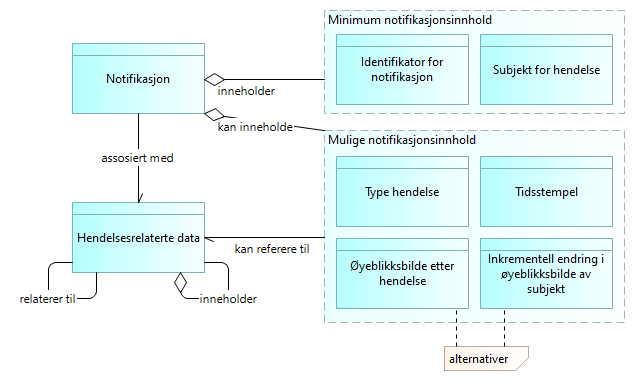
5.3.4. Notifikasjonsinnhold - basiskonsept UHF
Som et minimum må en notifikasjon inneholde en identifikator. Anbefalt innhold er basert på standarden CloudEvents (se Utvikling av ytre API i dette dokumentet)
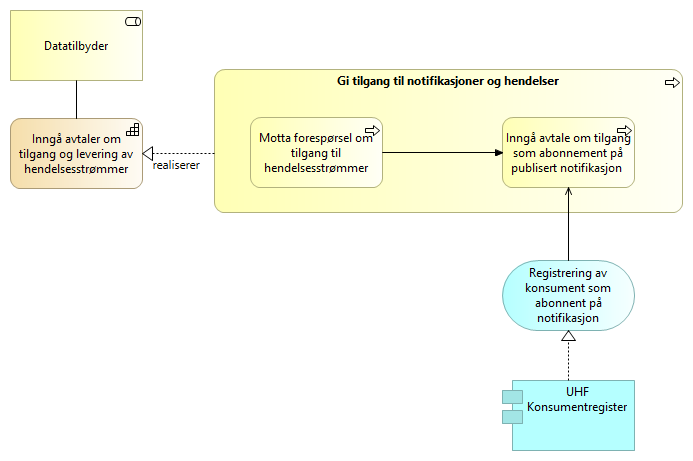
5.3.5. Inngå avtaler om tilgang og levering av hendelsesstrømmer - Publiser og Abonner UHF
Datatilbyder mottar forespørsel om å inngå avtale om tilgang og innhenting av hendelsesstrømmer Hendelsesstrømmen kan være i form av en hendelsesliste eller abonnement på et emne (notifikasjonskø).
5.3.6. Inngå avtaler om tilgang og innhenting av hendelsesstrømmer - Hendelsesliste og Publiser og Abonner UHF
Datakonsument inngår avtale om tilgang og innhenting av hendelsesstrømmer Hendelsesstrømmen kan være i form av en hendelsesliste eller abonnement på et emne (notifikasjonskø).
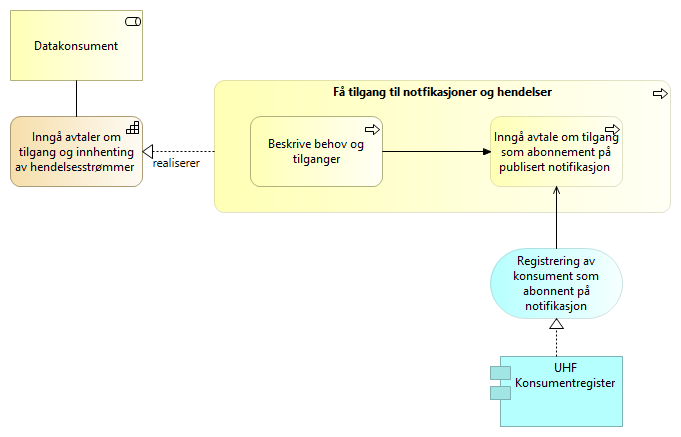
5.3.7. Generere og publisere notifikasjoner - Publiser og Abonner UHF
Datatilbyder publiserer en notifikasjon til en Notifikasjonsdistribusjon i form av en publisering/abonneringsløsning. Notifikasjonsdistribusjonen er realisert som en publisert kø per abonnent med et emne.
Datatilbyder publiserer notifikasjoner til disse køene når hendelser oppstår hos datatilbyder.
Hver enkelt abonnent har en innboks som abonnenten konsumerer. Notifikasjoner er transient og forsvinner fra innboksen etter at de er konsumert.
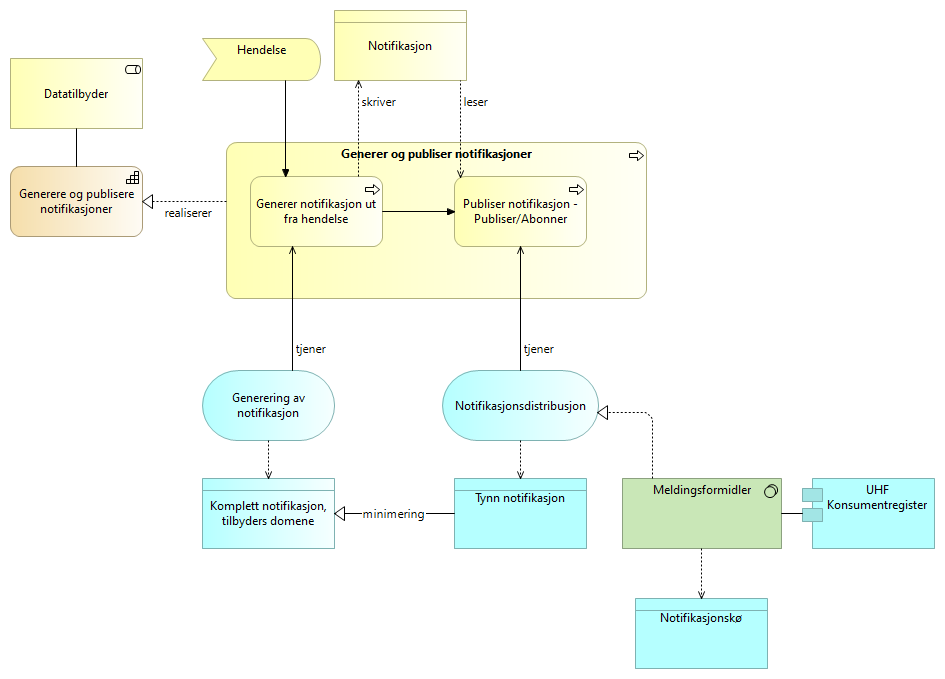
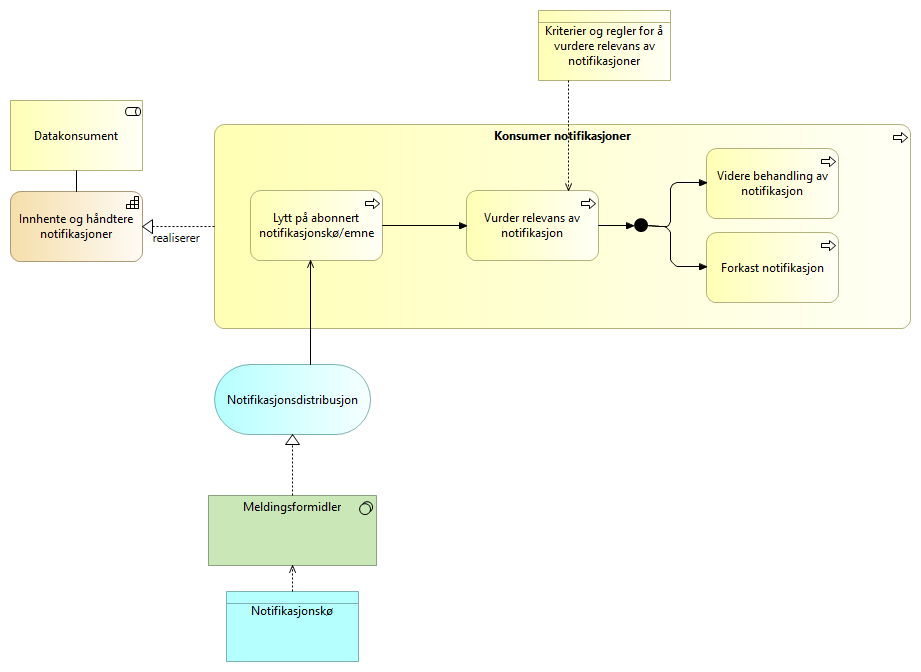
5.3.8. Konsumer notifikasjoner - Publiser og Abonner UHF
Datakonsument lytter på emner som konsumenten abonnerer på hos Datatilbyder. Når en ny notifikasjon kommer i notifikasjonskøen trigges konsumering av notifikasjonen.
Datakonsumenten vurderer relevans med basis i regler definert for abonnenten og foretar videre behandling av notifikasjon.
Videre behandling består av å gjøre et eOppslag (via API) som beskrevet i «Løsningsmønster forespørsel UHF» dersom konsumenten har behov for ytterligere informasjon om hendelsen beskrevet i notifikasjonen.
5.4. Oppdatering
Datatilbyder kan gjøre oppdatering av data tilgjengelig for datakonsument gjennom et API. Prosessen for en datakonsument å be om tilgang til oppdatering (se Få tilgang til data) og for en datatilbyder å gi tilgang til oppdatering (se Tilgjengeliggjøre data etter forespørsel) er tilsvarende som for tilgang til å lese data. Det vil ofte være forskjellige kriterier som må oppfylles for å få lov til å oppdatere data enn for å lese data. Dette kan inkludere både kvalitetssikring og juridiske hensyn.
5.4.1. Be om oppdatering - løsningsmønster i UHF sektoren
En prosessflyt en konsument utfører når det utføres et tjenestekall for å be om en oppdatering av data gjennom et API. API-adressen hentes i API-katalogen. Tilgang til APIet byttes inn mot et kjøretids-token i autoriseringstjenesten. Tjenestekall til APIet utføres gjennom API gateway der tokenet benyttes for å få tilgang.
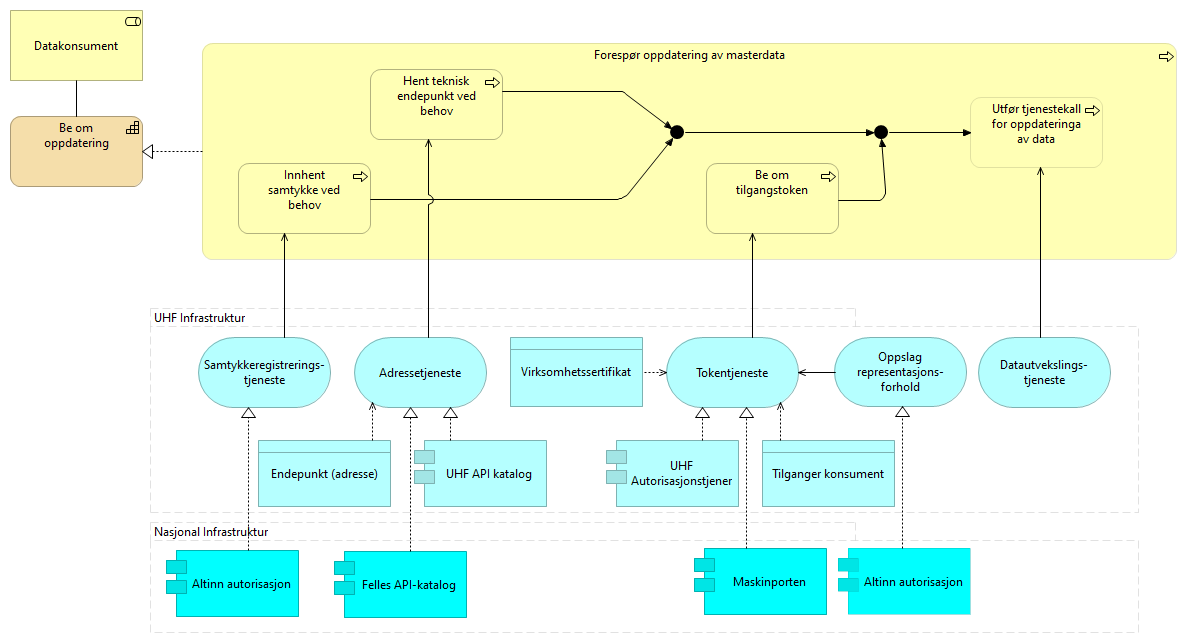
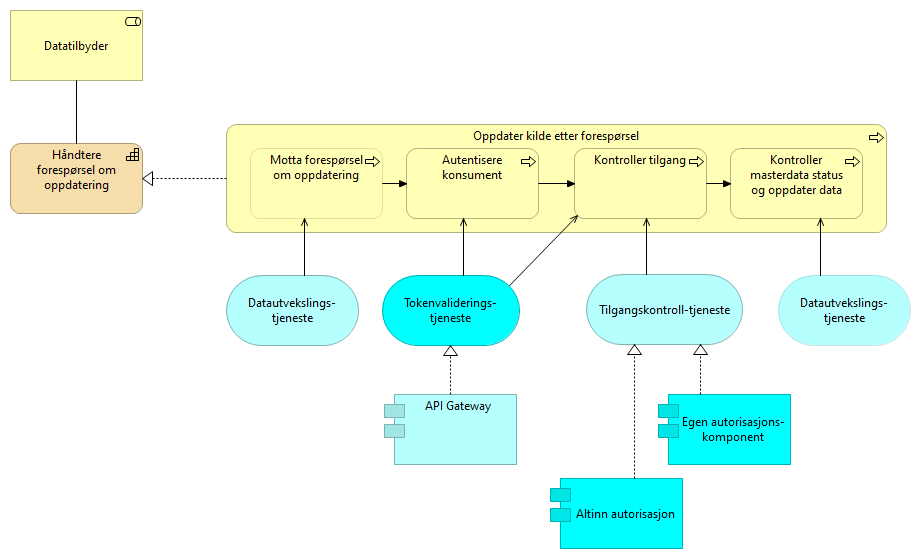
5.4.2. Håndtere forespørsel om oppdatering - løsningsmønster UHF
En prosessflyt en tilbyder av data utfører for å svare på en oppdateringsforespørsel. Tilbyder mottar forespørsel om oppdatering med et aksesstoken. Klienten som forespør autentiseres og token valideres. Eventuelt mer fin-granulert tilgangskontroll utføres og data oppdateres.
6. Rutiner
Vi forutsetter og bygger på en viss fremgang i arbeid med orden i eget hus hos deltagende virksomheter der noen datasett er dokumentert i en datakatalog. Dette kan enten være Digitaliseringsdirektoratets Felles datakatalog, eller en fremtidig katalog for høyere utdanning og forskningssektoren som høstes inn i Felles datakatalogen.
Vi skisserer en tilnærming til indre og ytre API basert på Gartners MASA arkitektur[4] som var brukt i evalueringen av Felles Studentsystem i 2020
6.1. Indre API
Indre API eksponerer masterdata (informasjon om objekter i domenet) som er strukturert i henhold til semantikk i domenet den tilhører, og må ta ansvar for den semantiske validiteten til data den eksponerer. Indre API er laget for å være mest mulig generell og ikke laget for noen spesifikk prosesskontekst.
[Vi tenker å utdype her på et senere tidspunkt.]
6.2. Ytre API
Ytre API benyttes i en forretningsprosesskontekst og datasett eksponert gjennom en ytre API er laget for å møte behovene til prosessen. Ytre API kan benyttes i både grunnleggende og bruksnære domener. En tilnærming til definisjon av APIer og datasett for prosesstøtte er beskrevet under.
-
Melde behov, gjerne av datakonsumentene
-
Tjenesteansvarlig kjører periodisk prosess for å samle innspill og prioritere
-
Vurder å kjøre tjenestedesign workshop for å beskrive bruksscenariene
-
-
Analysere behov og finne ut hvilke domener, kilder og datasett som er involvert
-
Tjenesteansvarlig identifiserer berørte interessenter, potensielt andre tjenesteansvarlige, dataforvalter, domeneansvarlig og begrepsansvarlig
-
Tjenesteansvarlig må vurdere og eventuelt sette i gang juridiske avklaringer omkring deling av data
-
-
Kjør begrepsharmonisering etter behov med relevante interessenter
-
Følg standarden om Begrepsharmonisering og begrepsdifferensiering og føringer fra Rammeverk for begrepskoordinering i KUDAF (kurs om begrepsarbeid er en utfyllende ressurs)
-
-
Publiser nye eller oppdaterte begreper i UHF begrepskatalog (eventuelt i begrepskatalogen under Felles datakatalog)
-
Identifiser hva må skapes, harmoniseres eller videreutvikles. Pass på at funksjonaliteten spesifisert i grensesnittet dekker kun det som trengs for å støtte brukstilfellet under utvikling som prinsipp for god design. I tillegg må all behandling av personopplysninger være adekvat, relevant og begrenset til det som er nødvendig for formålene de behandles for. Dette innebærer blant annet at det må vurderes om det definerte formålet kan oppnås med færre personopplysninger, eventuelt avidentifiserte opplysninger, samt at tilgangsvisning og lagringstid må søkes minimert til det som er nødvendig.
-
Sikre at data i alle steg i verdikjeden passer til den tenkte anvendelsen.
-
Definere API/datasett i team med representasjon fra både bruksmiljø og produsent. Det kan ta noen iterasjoner med utprøving av API før man er fornøyd. Senere oppdateringer kan kjøres som iterasjoner da man allerede har resultatene fra tidligere steg.
-
Designe nødvendig API for brukskonteksten.
-
Mappe nødvendig funksjonalitet til API fra grunnleggende domener.
-
Designe «API mediation», det vil si hvordan datasettet spesifisert i det ytre APIet tilgjengeliggjøres. Oppgaven inkluderer mapping til indre API som benyttes med nødvendig oversetting av protokoller, formater og datastrukturer, samt etterlevelse av policy for sikkerhet og volumbegrensninger.
-
Implementere tjenestene
-
Koordinere mellom APIene for å sikre sammenhengende brukeropplevelse mellom APIene
-
Publisere APIene og datasett i UHF API katalog (eventuelt felles datakatalog) i henhold til DCAT-AP-NO
-
6.3. Notifikasjoner
Når en hendelse endrer data hos en datatilbyder, og disse data deles
gjennom datadeling med notifikasjon, skal det sendes en notifikasjon til
datakonsument.
Notifikasjoner omhandler hvilke data i det tilhørende API som er endret.
Notifikasjonen er sådan operasjonell, den melder fra om hvilke data som er endret, men ikke hvilken forretningshendelse som har inntruffet.
For å utvikle notifikasjoner følges tilsvarende prosess som for API over. Det vil si at notifikasjoner, som beskrevet i denne referansearkitekturen, er knyttet til API der datakonsumenten henter ut data. Det vesentlige av beskrivelse for datautvekslingen ligger derfor til utviklingen av API som hører sammen med notifikasjonen.
Spesielt for notifikasjoner gjelder følgende:
-
Notifikasjonen skal gi en meningsfull indikasjon på hvilke data som er endret i form av liste over endrede attributter i datagrunnlaget.
-
Notifikasjonen skal inneholde en referanse til ressursen (i API-et) der data kan hentes fra
-
Etterstreb å modellere notifikasjoner etter etablerte standarder
-
Sørg for at meningen notifikasjonene bærer er godt dokumentert i notifikasjonskatalogen
-
Ressursen, det vil si det API som er knyttet til notifikasjonen, må være utformet slik at uthenting av data alltid gir siste gyldige versjon. På den måten vil innhenting hos datakonsument kunne være idempotent
Med «idempotent» er det i denne sammenheng ment at man kan kalle på den samme ressursen flere ganger og alltid få samme resultat.
Per i dag er CloudEvents den eneste generaliserte standarden for hvordan notifikasjoner bør utformes. Referansearkitekturen anbefaler at CloudEvents tas i bruk som standardformat for notifikasjoner. CloudEvents er utviklet i regi av Cloud Native Computing Foundation.
En notifikasjon utformet etter minstekravene til CloudEvents med JSON Event Format ser typisk ut:
{"id": "935ec740-d4a4-418d-b6c3-282d6fd2305b",
"specversion": "1.0",
"time": "2020-11-19T17:30:41.244Z",
"source": "urn:no-edu-orgreg:ntnu:ou:1260",
"type": "orgreg.v1.ntnu.dev.ou.create"}
I eksempelet på en notifikasjon ovenfor meddeles det at det har blitt opprettet en organisatorisk enhet ved NTNU med identifikatoren 1260.
Bruk av et felles notifikasjonsformat tilrettelegger for gjenbruk av komponenter på tvers av tjenester da en notifikasjon er velstrukturert og de informasjonsbærende elementer er strengt definert. I de tilfeller det er nødvendig å inkludere informasjonsbærende elementer som ikke er inkludert i standarden, er standarden mulig å utvide. Standarden legger også til rette for en rekke operasjonelle kapabiliteter (eksempelvis deduplisering) gjennom informasjonselementene som er påkrevet i standarden.
7. Vedlegg A; Definisjoner
Referansearkitekturen forutsetter at begreper vil bli definert i sine respektive domener og publisert i en begrepskatalog når referansearkitekturen realiseres. I mellomtiden kopierer vi utvalgte begreper fra data.norge.no med kildeangivelse for å bidra til en entydig forståelse av referansearkitekturen.
Datakvalitet innebærer at data skal være korrekte, komplette, oppdaterte og konsistente og har evnen til å støtte de informasjonsformål de brukes til [kilde: data.norge.no, SKATTEETATEN]
Masterdata: Autoritative data for gitte opplysningstyper. [kilde: data.norge.no, NAV]
Grunndata: Basisinformasjon innen en gitt sektor. [kilde: data.norge.no, NAV]
8. Vedlegg B; Behov for avklaringer og utfordringer i sektorenes kontekst
8.1. Issues mot nasjonale felleskompontenter (Maskinporten, ID Porten og Altinn autorisasjon)
-
Harmonisering av autorisasjon
-
Det er ønskelig at UHF autorisasjonstjener og Maskinporten godkjenner hverandres tilgangstokens. Dette forutsetter at informasjonsmodellen benyttet i tokens er felles. Løsningsvarianter:
-
Klienter forholder seg til flere autentiseringstjenere og tjenestetilbyderne standardiserer token strukturen
-
Innbytte av tokens (token exchange) fra andre “trusted” autorisasjonstjenere. En konsekvens av dette er at man mister (?) koblingen til bruker og dermed kjennskap til autentiseringsstyrken som ligger bak.
-
Software Statement Assertion (https://tools.ietf.org/html/rfc7521 – løsning benyttet av Open Banking UK
-
-
-
Harmonisering av samtykke
-
Altinn autorisasjon benytter «Self-contained OAuth2 token» for samtykke. Men da vi ikke kan godkjenne tokens på tvers, har vi utfordringer med å benytte Altinn autorisasjon direkte. I hvert fall dekker ikke tjenesten «scopes» vi har anvar for i UHF autorisasjonstjeneren.
-
Kan «User Managed Access (UMA)» være et alternativ her?
-
-
Delegering av authorisasjons-rettigheter: Altinn har per i skrivende stund (mai 2021) ingen god mekanisme for å delegere rettigheter under organisasjonsgranulariteten i Enhetsregisteret. UHF sektorene arbeider med mekanismer for authorisasjon og tilgangsstyring i sektorene våre. Det er ønskelig med en helhetlig nasjonal modell for authorisasjon og tilgangsstyring som fungerer på tvers av sektorer.
8.2. Issues internt i høyere utdannings- og forskningssektorene
-
Det er ønskelig at samme forretningslogikk ligger til grunn for tilgang til data uansett om det skjer via bruk av applikasjoner eller oppslag gjennom API. Koordinering mellom IAM prosjektet, UH Sak prosjektet og Datadelingsprosjektet er en forutsetning for denne harmoniseringen av funksjonalitet.
-
Dersom forskjellige autorisasjonstjenere ikke kan dele tokens, har vi det samme problemet vi har mot de nasjonale fellestjenestene at det ene domenet ikke kan forholde seg til tokens fra det andre domenet.
-
Sektoren har tre uavhengige SSO løsninger: IDporten, Feide og Azure AD. Dette gir både redusert brukervennlighet, og er en sikkerhetsutfordring dersom man ikke kan garantere for at det er samme person i de ulike SSO identitetene.
9. Vedlegg C; Integrasjonsprinsipper
Referansearkitekturen følger generelt DigDirs overordnede arkitekturprinsipper, men sektorene høyere utdanning og forskning har behov for mer spisset prinsipper for å rettlede arbeidet med systemintegrasjoner. Referansearkitekturen inneholder derfor integrasjonsprinsipper som er tilpasset dette delområdet innen datadeling.
9.1. Brukerorientert arkitektur
Arkitekturen er formgivende for tjeneste- og systemlandskapet, som igjen skal gjenspeile hva brukerne trenger. Stadige endringer er normaltilstanden. Derfor må arkitekturen være fleksibel, slik at den kontinuerlig kan tilpasses brukermassens skiftende behov.
9.2. Tjenesteorientert arkitektur
Integrasjonsgrensesnitt skal utformes slik at tjenester og bakenforliggende systemer kan flyttes og byttes ut uten at konsumenter av tjenesten må gjøre endringer i sin ende, og omvendt. Dette prinsippet legger føringer på hvilken programvare vi kan anskaffe, hvilke grensesnitt som tilbys av egenutviklede applikasjoner, og hvordan vi kobler sammen egenutviklede applikasjoner.
9.3. Tilgjengelige data
Data skal være tilgjengelig for konsumenter. Tilgjengelighet manifesterer seg på flere plan:
-
Teknisk.
-
Forståelsesmessig (semantisk).
-
Oppdagbare.
For at kravet om teknisk tilgjengelighet skal være oppfylt, må data tilbys gjennom åpne grensesnitt som er teknisk dokumentert, samtidig som det forutsetter at grensesnittet er tilgjengelig over tid og bakoverkompatibelt.
For at data skal være tilgjengelige forståelsesmessig, må dataenes semantiske betydning være dokumentert.
Oppdagbarhet forutsetter at definisjoner av grensesnitt og tilhørende teknisk og semantisk dokumentasjon er publisert. Avhengig av dataenes størrelse, struktur og bruksområde, kan det være nødvendig å melde fra til konsumenter om at data har endret seg ved å benytte notifikasjoner.
Se mer om dette under Utforming av notifikasjoner og Utforming av API.
Se gjerne:
-
Digitaliseringsdirektoratets arkitekturprinsipp 4: Del og gjenbruk data, spesielt:
-
Prinsipp 4.2: Tilby data i tråd med regjeringens Retningslinjer ved tilgjengeliggjøring av offentlige data.
-
Prinsipp 4.3: Gjenbruk data fra autoritative kilder. Bruk kopier kun der det er nødvendig, og sørg for at disse er oppdaterte.
-
Prinsipp 4.5: Unngå innlåsing av data i systemer.
-
9.4. Gjenbruk av løsninger
Gjenbruk av løsninger forutsetter at det samarbeides i fagmiljøer på tvers av institusjoner om å homogenisere forretningsprosesser.
-
Prinsipp 5.1: Kartlegg eksisterende og planlagte løsninger som kan være aktuelle å gjenbruke.
-
Prinsipp 5.8: Tilgjengeliggjør informasjon om, og tilby gjenbruk av egne løsninger som kan være interessante for andre.
9.5. Etterrettelig bruk av data
Konsum av API-er skal skje gjennom API Manager. Dette medfører at institusjonen har oversikt over hvem som konsumerer hvilke data.
9.6. Avvik må begrunnes
Avvik fra prinsippene om Tjenesteorientert arkitektur og Tilgjengelige data er lov, så lenge det kan begrunnes at avviket er hensiktsmessig for sektoren.
Et eksempel er at det kan være hensiktsmessig å bruke en leverandørspesifikk integrasjon, hvis kostnadene ved å innføre en løsere kobling blir høyere enn konsekvensene og risikoen for institusjonen ved å låse seg til en leverandør.
10. Vedlegg D; Behov og bruksområder
10.1. Forskning og læring
Det er behov for å videreutvikle datadeling for læring og forskning. I henhold til ny digitaliseringsstrategi skal studenter tilbys fleksible og studentaktive undervisningsformer. Data om studentenes læring forvaltes hos og tilbys fra den enkelte institusjonen. Institusjonen er ansvarlig for at data opprettholder nødvendig kvalitet, inklusiv samordning med relaterte datakilder. Data om gjennomført utdanning er lett tilgjengelig gjennom hele livet.
Dette krever endringer i informasjonsforvaltningspraksis. Praksisen må kunne støtte læringsprosessen på en måte som gir studenten mulighet til å utnytte egne data for best mulig læring.
Forskning må gjøre tilgang til resultater og data lettere. Forskningsgrupper som kan inkludere deltagere fra Norske institusjoner, utenlandske institusjoner og næringslivet skal ha enkel tilgang til data når de har rett til det.
For å være smidig og effektive må virksomhetsprosesser som understøtter
læring og forskning enkelt kunne gjenbruke dataressurser nasjonalt.
Disse dataressurser inkluderer læringsressurser, undervisningsressurser,
datasett og forskingspublikasjoner.
10.2. Administrative prosesser
Behovene til datadeling i høyere utdanning og forskning forsterkes av at det er identifisert store, akutte behov knyttet til deling av data mellom administrative tjenester.
Kjerneprosessene hos institusjonene må støttes med administrative data, slik at personer og organisasjoner får støtte for saksbehandling og annen nødvendig drift av organisasjonene. Dette gjelder særlig de store prosjektene i BOTT-regi for etablering av fellesløsninger på økonomi og lønn (BOTT:ØL) og saksbehandling og arkiv (BOTT:SA) og et felles identitets- og tilgangsstyring (IAM). Disse skal dekke helt sentrale arbeidsprosesser i sektoren.
Saksbehandlingsstøtte innen forskningsfinansiering kan også automatiseres ved hjelp av tjenestekjeder i datadelingsplattformen.
10.3. Gjenbruk og viderebruk av data
For å gi fleksibel og effektiv støtte for behovene over skal data som benyttes i virksomhetens sentrale prosesser plasseres i kilder som er modulære og kan kobles til de prosesser som trenger de.
Disse kilder defineres som «masterdatakilder» og de inneholder informasjon om blant annet studenter, ansatte, organisasjoner, emner, forskningsprosjekter, og vitenskapelige resultater.
Data fra disse kildene blir gjenbrukt i de ulike arbeidsprosesser som har behov for dem. I tillegg til de mest sentrale virksomhetsprosesser, blir data fra masterdatakilder også brukt på nye måter (viderebrukt). Disse kan være spesifikke for enkeltbrukere, som for eksempel evaluering av et emne.
Når dataressurser er lett tilgjengelig, kan sektoren oppnå mer brukernær
innovasjon.
Det innebærer at blant annet studenter, lokale IT-avdelinger og Ed Tech
leverandører, gis mulighet til å bygge lettvekts brukerapplikasjoner
gjennom tilgang til data.
Dette kan være både fra de tunge tjenestene og mer smale tjenester som
timeplan-/bookingsystem, posisjonsdata, etc.
10.4. Datakonsumenter
I tillegg til behov knyttet til funksjonsområdene læring, forskning og administrasjon er det behov knyttet til utvidelse av hvem man har tenkt å dele data med.
Målsetningen i første fase av UH:IntArk har vært deling av
virksomhetsinterne data i interne forretningsprosesser, herunder også
deling av disse med tjenester som ligger på utsiden av virksomheten og
som understøtter virksomhetens forretningsprosesser. Eksempler på slike
tjenester er økonomi- og lønnstjenester, sak og arkiv, og så videre.
Det som kjennetegner dataflyten i denne dimensjonen, er at dataene
betraktes som virksomhetsinterne og ikke ønskes delt til 3. part ut over
spesifikke forretningstjenester på utsiden av virksomheten.
Denne referansearkitekturen omfatter også deling av data til 3. part, det vil si at dataene skal eksponeres på utsiden av virksomheten. Slike data omfattes av orden i eget hus og skal i henhold til digitaliseringsrundskrivet beskrives i
-
en felles datakatalog
-
en felles API-katalog
-
en felles begrepskatalog,
Disse skal ligge i Digdirs Felles datakatalog (data.norge.no).
Per februar 2021 tilbyr ikke Digdir noen felles autorisasjonstjeneste knyttet til API som er beskrevet i API-katalogen.
Det betyr at autorisasjon må håndteres, i ytterste konsekvens, av den enkelte API-eier. Referansearkitekturen beskrevet her tar høyde for at dette kan håndteres som en fellestjeneste i høyere utdanning og forskning.
10.5. Overordnede behov
De viktigste overordnede behovene adressert i referansearkitekturen for datadeling i høyere utdanning og forskning er:
-
Sikre at UHF følger de Overordnede arkitekturprinsippene for digitalisering av offentlig sektor
-
Sikre at sektoren har en enhetlig og sikker måte for å håndtere tilganger til sektorens data gjennom kravstilling utrykt i referansearkitekturen
-
Sikre at referansearkitekturen utnytter/samhandler med nasjonale felleskomponenter der disse kan dekke sektorens behov på en tilfredsstillende måte, jamfør Digitaliseringsrundskrivet 2020, kap. 1.5 Bruk nasjonale felleskomponenter og fellesløsninger3
-
Sikre effektiv datautveksling mellom virksomheter i UHF og med andre sektorer
-
Sikre at data som sektorens virksomheter eksponerer utad, er beskrevet på en måte som gjøre det enkelt for konsumenter å få kjennskap til hvilke data som er tilgjengelig, hva de beskriver (ved hjelp av begreper som er beskrevet og harmonisert), kriterier for tilgang til bruk av dataene og beskrivelse av API som benyttes for å aksessere dataene
-
Sikre tilstrekkelig kvalitet i data som er delt gjennom felles forvaltningsroller og -prosedyrer
-
Sikre at API, datasett og hendelser tilgjengeliggjort defineres i henhold til konsumentenes behov gjennom prosedyrer for samspill mellom datakonsument og datatilbyder
-
Sikre forvaltning og videreutvikling av API, datasett og hendelsesnotifikasjoner på en måte som både sikrer drift og muliggjør innovasjon (lifecycle management)
10.6. Bruksområder for datadeling
Datadeling skal støtte virksomhetene innen høyere utdanning og forskning i sine oppgaver. Arbeid med referansearkitekturen tar derfor utgangspunkt i følgende bruksområder som første steg i en brukerfokusert tilnærming:
-
Innovativ, individuelt tilpasset læring
-
Livslang læring
-
Forskning
-
Automatisert administrativ støtte
-
Forskningssøknader
-
Datahåndteringsplan innen forskning og andre prosjekter
-
Arkivering
-
HR prosesser for ansettelse og utsjekk
-
Innen bruksområdene over ser vi sektoren produserer og ønsker å tilby følgende hovedkategori av data for deling:
-
Utdannings- og forskningsressurser til gjenbruk og viderebruk
-
Forskningsresultater
-
Forskningsdata
-
Digitale læringsressurser
-
-
Administrative data
-
Grunndata for driftsformål
-
Data brukt og produsert i saksbehandling
-
Rapporteringsdata om egen saksbehandling og produksjon
-
-
Analysedata om utdanning og forskning
Sektoren har også bruk for data fra andre. Vi ser behov for følgende kategori av data:
-
Grunndata i nasjonale felleskomponenter (for eksempel fra folke- og enhetsregister)
-
Autentiseringsdata fra utlandet
-
Informasjon om grunnutdanning i Norge
-
Informasjon om utdanning i utlandet
-
Informasjon om forskning i utlandet og forskningsresultater fra utlandet
-
Informasjon om forskning i privatnæringsliv og resultater fra forskning i privat næringsliv
-
Informasjon om forskningsfinansiering i Norge (fra Forskningsrådet, med flere)
Bruksområdene over er utgangspunktet for forståelse av behovene som referansearkitekturen skal dekke.
11. Vedlegg E; Føringer
Dette dokumentet beskriver de føringene til organisasjoner og IT-løsninger som vi ønsker å bruke videre i sektoren til å skape en effektiv plattform for datadeling. Referansearkitekturen tar utgangspunkt i følgende pågående arbeid i sektoren i dag:
-
Datadeling - UH:IntArk
-
Arbeid med Sak og Arkiv i sektoren
-
Arbeid med nytt API for Felles Studentsystem, FS
-
Arbeid med masterdatakilder for forskning
Referansearkitekturen innarbeider også føringer fra:
-
Digitaliseringsstrategiene til offentlig sektor og høyere utdanning og forskning
-
Overordnede arkitekturprinsipper for digitalisering av offentlig sektor
-
Nasjonal referansearkitekturene for datadeling og datautveksling
-
Capability model from EUNIS (European University Information System Organization), for tiden under endring, basert på HERM (Higher Education Reference Model, basert på CAUDIT, UCISA, EDUCAUSE og EUNIS) kapabilitetsmodell
-
Behovene avdekket i tjenestedesign analyse av behovene til Studenter, Lærere, Forskere og tjenesteleverandører av et "Muliggjørende økosystem".
En viktig forutsetning for videre arbeid med samhandling og datadeling er Digitaliseringsdirektoratets «Orden i eget hus»:
«Med orden i eget hus mener vi at “den enkelte virksomhet skal ha oversikt over hvilke data den håndterer, hva dataene betyr, hva de brukes til, hvilke prosesser de inngår i, og hvem som kan bruke dem (informasjonsforvaltning)֦ . Dette innebærer også å ta stilling til hvilke data som kan gjøres tilgjengelig for gjenbruk i offentlig sektor, og viderebruk av privat sektor. Offentlige virksomheter må prioritere utveksling av informasjon som andre virksomheter har krav på (Digitaliseringsrundskrivet).”
Referansearkitekturen forutsetter at virksomheter i UHF-sektoren har gjennomført eller er i gang med å gjennomføre prosesser for å skape «orden i eget hus».
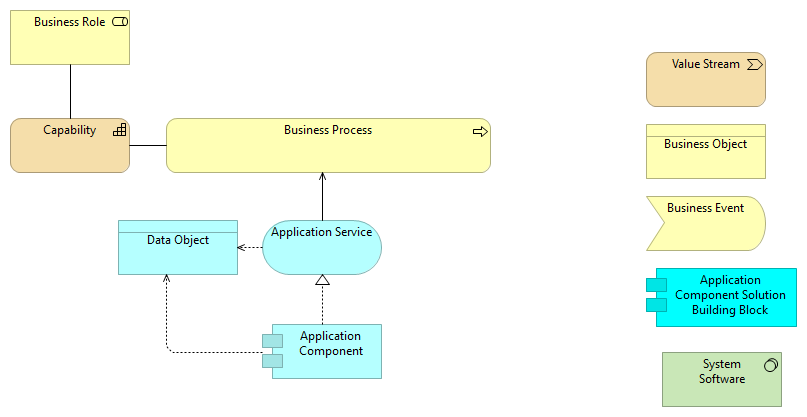
12. Vedlegg F; Bruk av Archimate
The ArchiMate Enterprise Architecture Modeling Language is used by this refererence architecture.
Selected symbols from the language that are used in this architecture are described in the element table below. Obects are represented as "architectural building blocks" (ABBs) and Solution Building Blocks (SBBs). The ABBs have a lighter color than the SBBs.
Architecture Building Blocks (ABBs) define what functionality will be implemented.
Solution Building Blocks (SBBs) define what products and components will implement the functionality. SBBs are product or vendor-aware.
Many of the diagrams in this architecture are organized as indicated in the figure below. An actor performing a particular business role creates the described capability through a business process. This business process will typically be supported by application services which are realized through application components. Both applications services and application components may access data objects.