Tilnærming til utvikling av referansearkitekturen
Denne referansearkitekturen skal gi veiledning til utforming av digitale samhandlingsløsninger for deling av data i høyere utdanning og forskning. Denne seksjonen gir veiledning om hva som skal oppnås gjennom en presentasjon av hva datadeling er, en visjon om hva vi skal bruke det til, og modellene som skal skape fundament for utforming av løsningene i visjonen.
1. Hva er datadeling
Følgende definisjon for datadeling er hentet fra Digitaliseringsdirektoratets temaområde for datadeling.
Vi tolker definisjonen til å gjelde uansett om data flyttes til konsumenten eller om konsumenten får tilgang til data hvor de ligger. Innen forskning, for eksempel, kan det være hensiktsmessig å gi konsumenter av veldig store datamengder tilgang til å utføre analyse på data der de ligger.
2. Et økosystem for datadeling
I arbeidet med denne referansearkitekturen har vi tatt utgangspunkt i en idé om samhandling mellom ulike parter i et større hele. Dette er basert på visjonen om et økosystem, der aktører utfyller hverandre og samhandlingen skaper større verdi enn de enkelte aktører kan klare hver for seg. Studenter, undervisere, forskere og tjenestetilbydere med flere skal både skape, tilby, bearbeide og konsumere data på nye måter som gir alle insentiv og gevinst. I økosystemet for deling av data i høyere utdanning og forskning ser vi for oss de forskjellige aktørene i forskjellig kontekst kalt domener (se seksjonen under). Økosystemet skal etableres opp på en datadelingsplattform, og elementene i plattformen er spesifisert i referansearkitekturen.
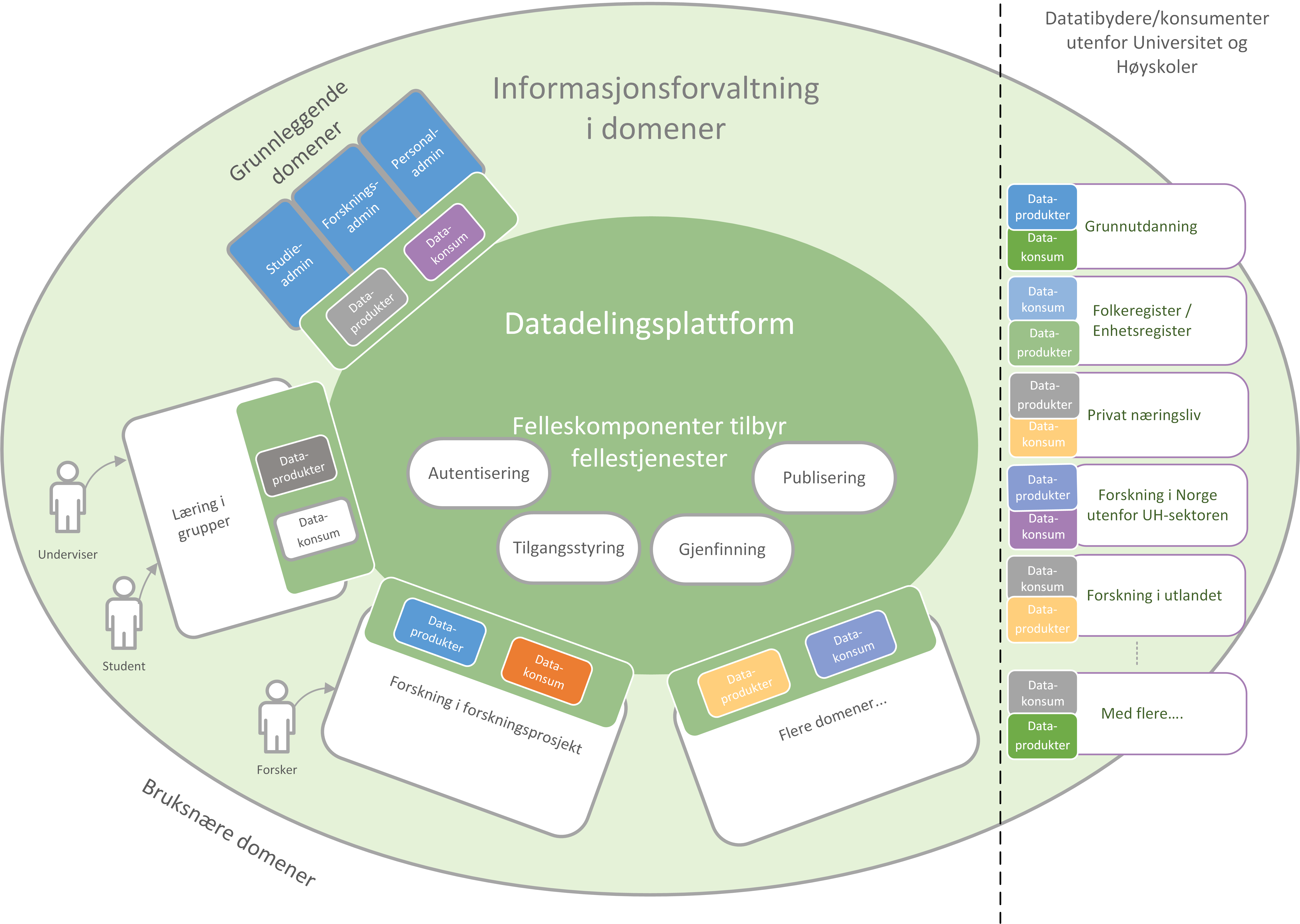
Figuren viser datadeling i og mellom domener. Dataprodukter tilgjengeliggjøres og deles mellom domenene i økosystemet. Domenene kan opptre som datatilbydere (tilbyr dataprodukt) og datakonsumenter (datakonsum). Datadelingsplattformen og fellestjenestene i den muliggjør datadelingen i økosystemet.
3. Domener
Informasjonen som skal forvaltes finnes i en faglig kontekst som vi kaller et «domene».
Innen et domene definerer et fagområde sine begreper i det vokabularet som benyttes der. For eksempel vil et begrep som «Søker»[1] ha en beskrivelse, forståelse og sine egne data i et studieadministrativt domene.
Som en del av den generelle utvikling innen IT systemer, er høyere utdannings- og forskningssektorene i ferd med å bygge en distribuert arkitektur som knytter sammen løst koblede, delte datakilder. Referansearkitekturen er laget for å støtte denne utviklingen ved å benytte domener som utgangspunkt for informasjonsforvaltning, utvikling av datakilder, datasett, API og hendelser.
Referansearkitekturen beskriver en datadelingsplattform som støtter deling av data mellom domener gjennom både API og publisering av hendelser. Vi grupperer domenene i grunnleggende domener og domener utviklet for spesielle brukstilfeller som avbildet under.
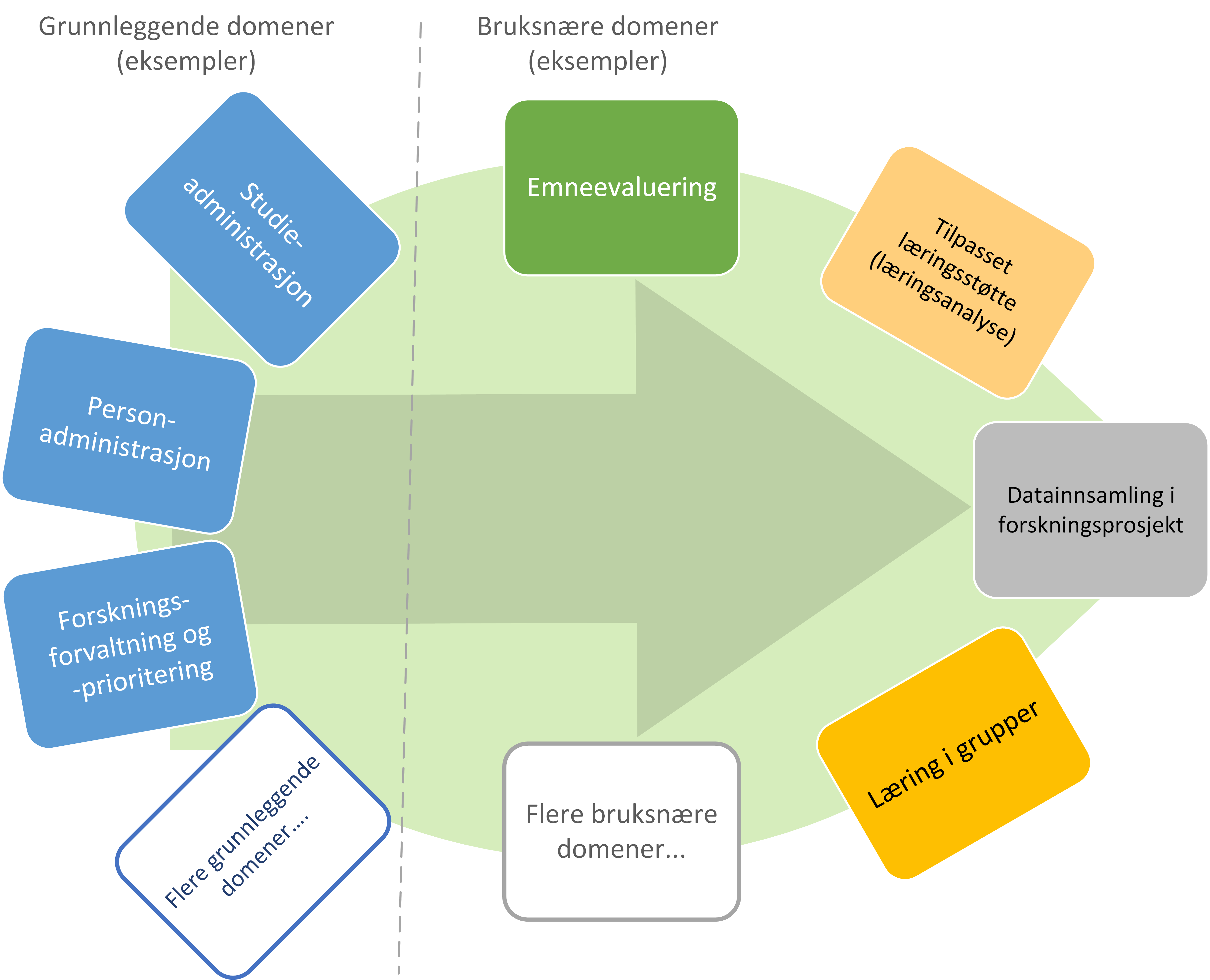
De grunnleggende domenene inneholder kontekst som støtter de sentrale prosessene for læring, forskning og administrasjon hos institusjonene. Denne konteksten vil omfatte begreper, informasjonsmodeller, prosesser og dersom det er hensiktsmessig, også data.
Disse domenene inneholder blant annet masterdatakilder med informasjon om, for eksempel, studenter, ansatte, forskningsprosjekt, forskningsresultater, læringsobjekter, med flere. Den semantiske betydningen av objektene og deres attributter i masterdatakildene skal reflektere en omforent forståelse av disse begrepene. Disse kildene er definert ut fra en dyp forståelse av sektorenes funksjon og vil typisk være forholdsvis stabile over tid.
API og datasett definert i grunnleggende domener blir gjerne gjenbrukt av bruksnære domener.
De bruksnære domenene er definert til å støtte en spesifikk brukskontekst. Domener for brukskontekst inkluderer for eksempel situasjoner der studenter evaluerer emner, der studenter får automatisert tilbakemeldinger for å forbedre læringsprosessen (læringsanalyse) og der deltagere i forskningsprosjekt samler data.
Datasett og API definert her skal være spesifikke og skreddersydd til brukskonteksten.
Vi har hentet denne tilnærmingen fra faglitteratur om Data Mesh[2] av Zhamak Dehghani. Arkitekturen påvirker rutiner for utvikling av API, datasett og notifikasjoner beskrevet i seksjonen Rutiner samt roller og ansvar beskrevet i seksjonen Roller og ansvar for datadeling og informasjonsforvaltning.
4. Hva er felles
Domenene beskrevet over, og rollene knyttet til disse får en definert avgrensning. Tilnærmingen til avgrensing følger fra strategiske valg i Handlingsplanen for digitalisering i høyere utdanning og forskning. Disse valg er knyttet til hva som skal være standardisert, hva som skal være felles og hva som skal variere og fremme innovasjon. Administrasjons- og støtteprosesser skal i størst mulig grad benytte standardiserte arbeidsprosesser og felles begreper. Lærings- og forskningsprosesser skal fremme innovasjon gjennom arbeidsprosesser som understøtter faglig autonomitet. [3]
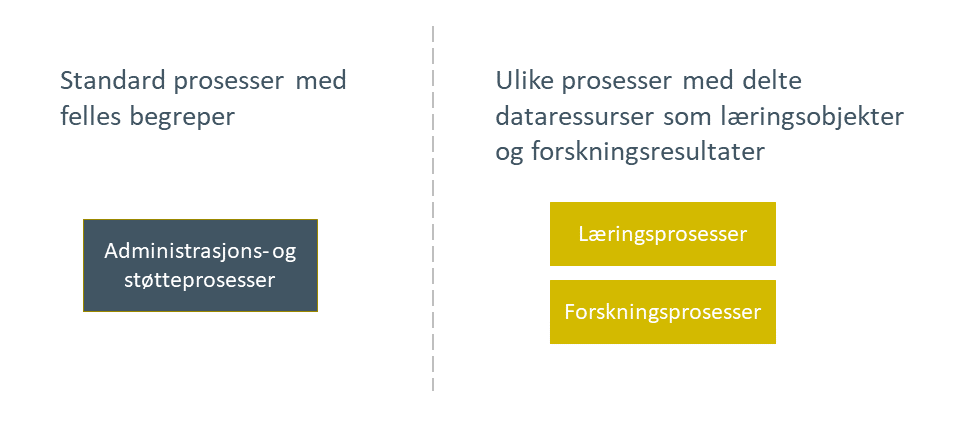
Disse ulike tilnærmingene har ulike behov for deling av data, og vi har benyttet disse føringene i avgrensning av domenene og rollene i referansearkitekturen.
Administrative prosesser og begreper skal være mest mulig standardisert. For å oppnå dette knyttes de til informasjonsdomener som representerer sektorene som helhet der definisjon av prosesser og begreper skal skje. Denne tilnærming er i tråd med eksisterende harmoniseringsprosesser i sektorene. Samtidig er data som inngår i de standardiserte, administrative prosessene hovedsakelig lokale data for den enkelte institusjon hvor prosessen kjøres.
Lærings- og forskningsprosesser vil variere og være knyttet til en brukskontekst med et tilhørende informasjonsdomene. Aktører knyttet til bruksnære lærings- og forskningsdomener vil typisk ønske en bred tilgang til lærings- og forskningsressurser produsert av andre hos institusjonen, nasjonalt og internasjonalt. Det kan også være ønskelig å publisere resultater fra bruksdomer bredt. Brukernære domener innen læring og forskning vil derfor ønske støtte til å dele ressurser på tvers av institusjonene. Eksempler på tjenester som muliggjør slik datadeling er Nasjonalt Vitenarkiv og eventuelle «Learning Object Repositories».
5. Samhandling og datadeling
Når datatilbydere og datakonsumenter deler data, skjer det som en del av en digital samhandling. For at samhandlingen skal være vellykket, må tilbydere og konsumenter sikre at de handler i henhold til loven (juridisk samhandlingsevne), at aktørene har avklart forventninger til hverandre og klarer å samarbeide (organisatorisk samhandlingsevne), at datatilbydere og konsumenter har samme forståelse av dataenes betydning (semantisk samhandlingsevne) og at de tekniske løsningene som utfører datadeling fungerer sammen slik de skal (teknisk samhandlingsevne). Rammeverk for digital samhandling vist under utdyper disse samhandlingsevnene.
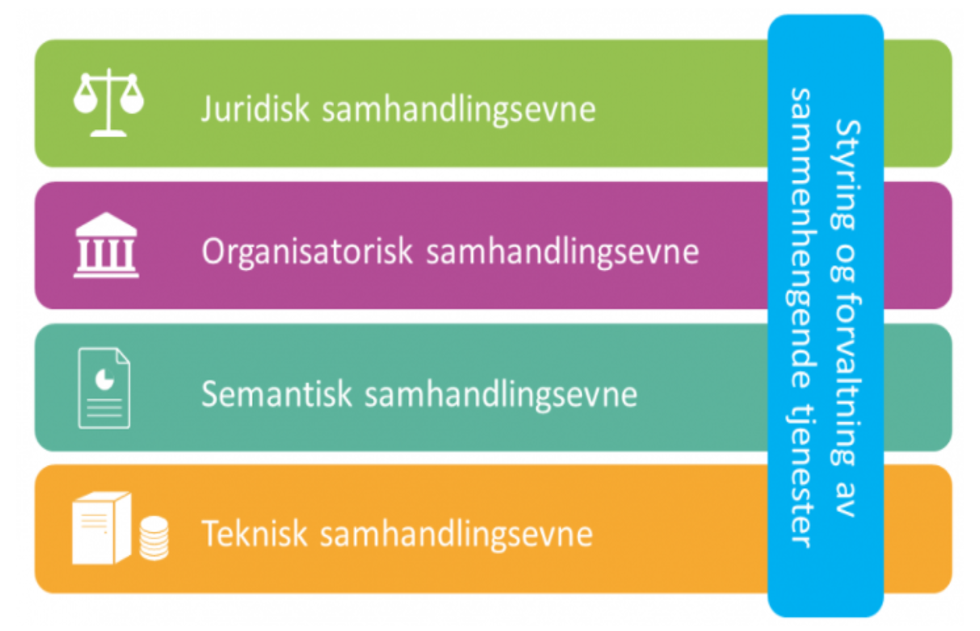
Modellene som er utgangspunkt for referansearkitekturen for deling av data i høyere utdanning og forskning er laget for å ivareta juridisk-, organisatorisk-, semantisk- og teknisk samhandlingsevne og hjelper dermed de som benytter modellene til å lykkes med digital samhandling.
6. Verktøykassen for deling av data
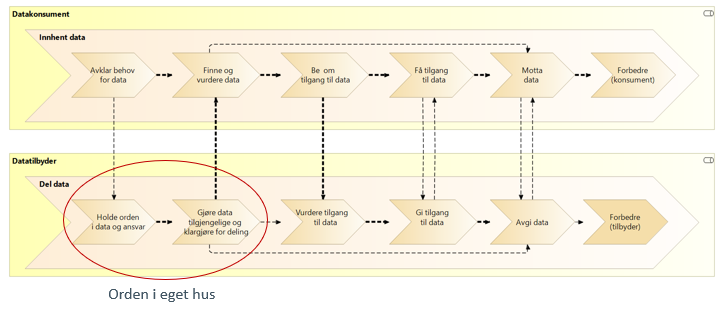
Verktøykasse for deling av data fra Digitaliseringsdirektoratet gir veiledning for de som skal bruke data fra andre (datakonsumenter) og de som skal dele data med andre (datatilbydere). Den overordnede prosessen brukt av datakonsumenter og datatilbydere for å dele data er beskrevet i verktøykassen og avbildet under.
Modellen beskriver verdistrømmer for både de som skal bruke data fra andre (datakonsumenter) og for de som skal dele data med andre (datatilbydere), samt forholdet mellom disse to verdistrømmene.
Verdistrømmene viser hvilke steg en datakonsument må gjennom for å motta data, og hvilke steg en datatilbyder må gjennom for å avgi data. Enkelte steg i verdistrømmene er tilpasset høyere utdannings- og forkninssektorene i referansearkitekturen. Dette er beskrevet senere i dokumentet
Før datatilbyderen kan utføre det første steget i verdistrømmen for datadeling må organisasjonen ha oversikt over egne data som skal deles. For å kunne utføre det andre steget i verdistrømmen må datatilbyderen ha evnen til å publisere datasettene slik at andre kan benytte disse. Disse stegene er sentrale i «orden i eget hus». For at datadeling skal fungere etter hensikten, må dataene også ha god kvalitet. Dette krever kapabiliteter innen informasjonsforvaltning. Vi har modellert disse evner som «muliggjørende kapabiliteter» i referansearkitekturen for høyere utdanning og forskning med utgangspunkt i EUNIS sin kapabilitetsmodell for europeiske universiteter som vist under. EUNIS modellen er utviklet gjennom som et samarbeid mellom europeiske universiteter.
7. Muliggjørende kapabiliteter
For å være i stand til å utføre stegene i prosessen over, må organisasjoner opparbeide evner, kalt «kapabiliteter». Noen kapabiliteter er knyttet til bestemte steg i verdistrømmen over. Andre kapabiliteter er generelle og «muliggjørende» for alle steg i verdistrømmen.
God informasjonsforvaltning støtter både opp om organisatorisk samhandlingsevne gjennom å gi organisasjoner riktig data av god kvalitet og støtter opp om semantisk samhandlingsevne ved å klargjøre dataenes betydning.
Vi velger også å synliggjøre juridiske tjenester som muliggjørende kapabilitet for å støtte opp under juridisk samhandlingsevne. Alt i alt krever digital samhandling kapabiliteter som er tverrfaglige, der ingen kan fungere uten de andre.

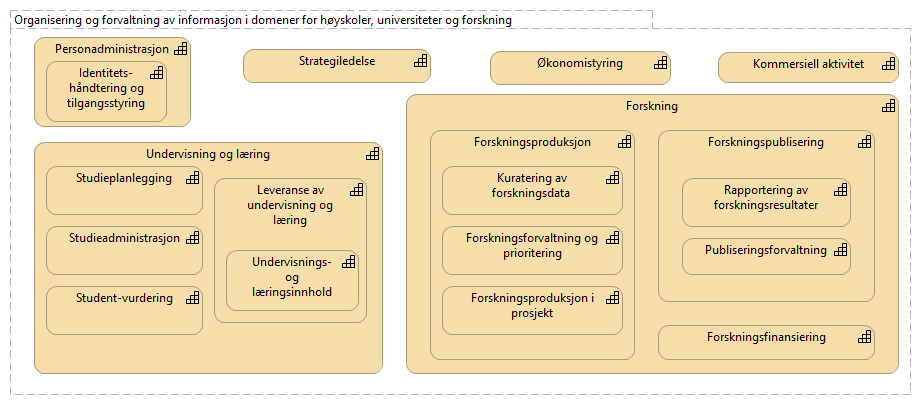
8. Organisering og forvaltning av informasjon i domener for høyskoler, universiteter og forskning
Hvert domene har sin egen informasjon som må forvaltes. Referansearkitekturen foreslår roller som har dette ansvaret i seksjonen Roller og ansvar for informasjonsforvaltning. Informasjonsforvaltning basert på domeneansvar forutsetter at høyere utdannings- og forskningssektorene blir enige om hvilke domener de skal forholde seg til og hvem som skal bekle rollene koblet til dem. Sektorene er allerede i gang med å definere funksjonsområder som kan være utgangspunktet for definisjon av informasjonsdomener. Arbeidet skjer både som analyse av evner (kapabiliteter) som virksomhetene skal ha og som en kartlegging av sektorenes kjernevirksomhet i en «funksjonsanalyse» for saksbehandlings- og arkiveringsformål.
Europeiske universiteter har modellert sine kapabiliteter i EUNIS kapabilitetsmodellen, en modell som nå gradvis migreres inn i HERM fra CAUDIT, støttet av EDUCAUSE og UCISA. Disse modellene er brukt som utgangspunkt for å foreslå noen informasjonsforvaltningsdomener for data som institusjonene ønsker å dele. De foreslåtte domenene er vist i figuren under. Innenfor hver domene har fageksperter eierskap til begrepsdefinisjoner i domenet.
Arbeidet med funksjonsanalyse for arkiveringsformål er en annen kilde til definisjon av informasjonsdomener. NTNUs representasjon av HERM fra CAUDIT med mapping til funksjonsanalysen er tilgjengelig her.