Sammendrag
1. Hva er en referansearkitektur?
Digitaliseringsdirektoratet sier at Referansearkitekturer gir veiledning til utforming av arkitekturer og løsninger, ut fra erfaring eller som målbilder. Valg av innhold avhenger av hva man vil oppnå og konteksten den skal brukes i. Referansearkitekturer kan være konkrete, slik som en veiledning for å sette sammen et møbel. Referansearkitekturer kan også være abstrakte, slik som Rammeverk for digital samhandling som veileder utforming av digitale tjenester. Begge varianter kan være svært nyttige, til hvert sitt bruk.

Figur 1 Spennet fra en konkret referansearkitektur for møbelbygging til en abstrakt referansearkitektur eksemplifisert med Rammeverk for digital samhandling fra Digitaliseringsdirektoratet
Referansearkitekturen for deling av data i høyere utdanning og forskning skal veilede helhetlig, operasjonell datadeling på en måte som støtter læring, forskning, innovasjon og administrasjon. For å oppnå denne målsetningen må den inneholde veiledende modeller som spenner fra det praktiske til det abstrakte. Referansearkitekturen inneholder modeller som støtter to hovedformål:
-
Etablere praktisk datadeling gjennom en teknisk datadelingsplattform som består av felleskomponenter, deres tjenester samt felles prosesser for deling av data
-
Skape informasjon av hensiktsmessig kvalitet slik at data som deles på plattformen har ønsket verdi
Figur 2. skisserer datadelingsplattformen som den mørke ellipsen i midten av figuren. Plattformen er en del av en større praksis for informasjonsforvaltning, vist som den større, lysegrønne ellipsen.
2. Forventet gevinst
Referansearkitekturen skisserer ønsket infrastruktur og beste praksis som øker oversikt og kontroll over data, samt forbedrer datakvalitet. Økt oversikt muliggjør reduksjon av kompleksitet og kostnad når unødvendige kopier av data og varianter av begreper fjernes. I tillegg vil oversikten gjøre det enkelt å finne relevante data for gjenbruk/viderebruk. Økt oversikt og kontroll muliggjør bedre sikkerhet og personvern. Når brukerne får tilgang til minimale og tilpassede datasett av høy kvalitet til sitt bruk, vil effektivitet, endringsdyktighet og innovasjon økes. Samhandling forbedres gjennom felles forståelse av data, tilgang til hverandres data og støtte for faglig kontekst i domener med tilhørende roller som har definert ansvar. Datadeling gir i tillegg et bedre grunnlag for kunnskapsbaserte beslutninger.
3. Datadelingsplattformen
Det første formålet med referansearkitekturen er å skape et en ønsket datadelingsplattform som skissert i den indre ellipsen i Figur 2. Figuren viser noen fellestjenester i midten som er realisert av felleskomponenter, som skal benyttes av datatilbydere og datakonsumenter for å dele data.
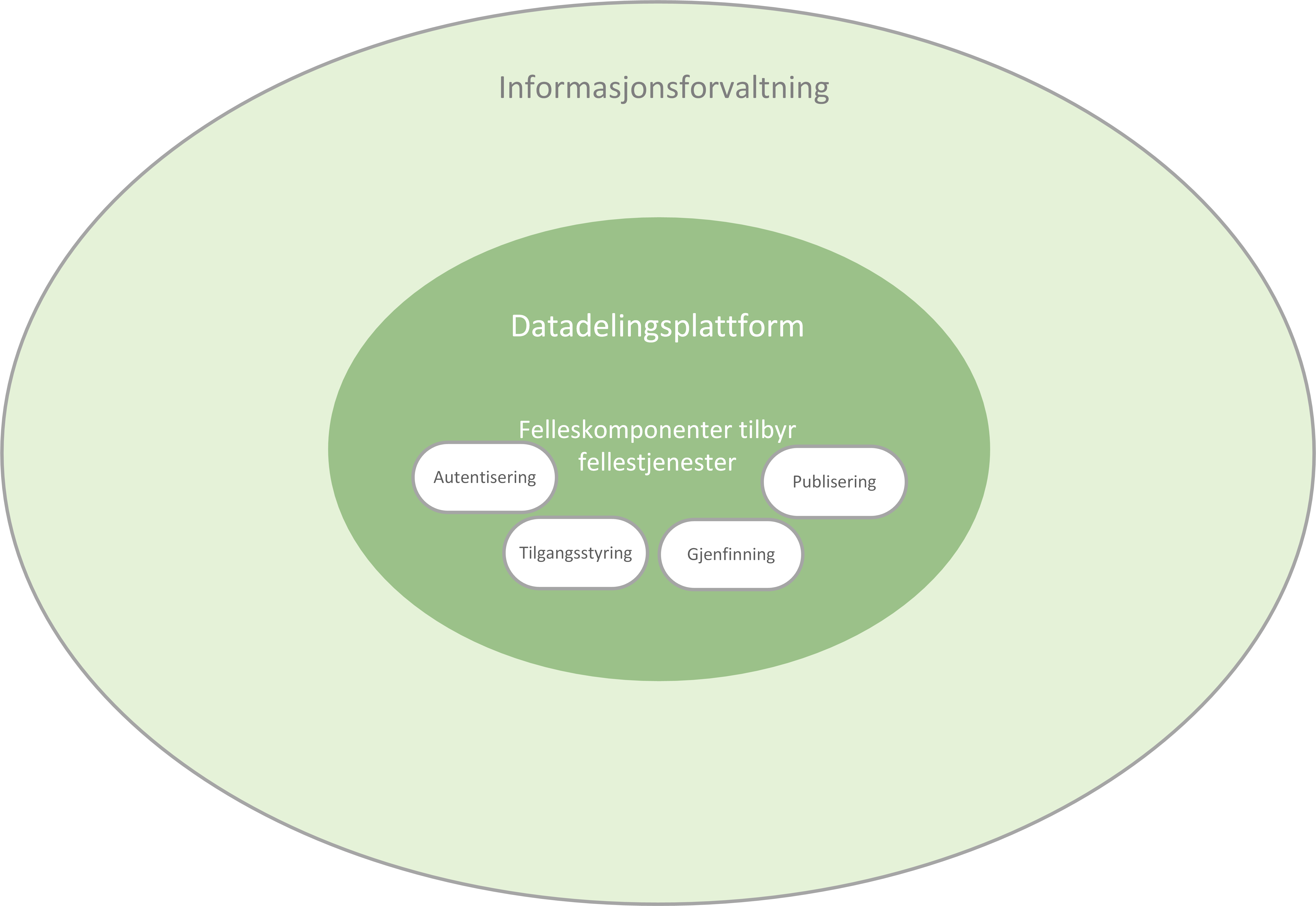
Figur 2 Datadelingsplattform med fellestjenester
Tjenestene utfører publisering og gjenfinning av data som er distribuert hos mange datatilbydere gjennom en sentral ressursportal. Denne tilnærmingen sikrer både at konsumenter lett kan gjenfinne data fra alle tilbydere på ett sted samtidig som datatilbydere beholder råderett over hvem som får tilgang til sine data. Data blir forvaltet hos datatilbydere som kjenner betydningen av dem og kan sørge for tilgjengeliggjøring av oppdatert data rett fra kilden. Denne tilnærming fremmer gjenbruk av data slik at endringer kan skje raskt og effektivt kun ett sted, kun en gang. Denne tilnærmingen fremmer i tillegg datadeling på tvers av virksomheter på plattformen.
Disse tjenester benyttes i datadelingsprosesser. Den mest overordnede prosessen for datadeling i referansearkitekturen er spesifisert i verktøykassen for deling av data fra Digitaliseringsdirektoratet og er vist i Figur 3.
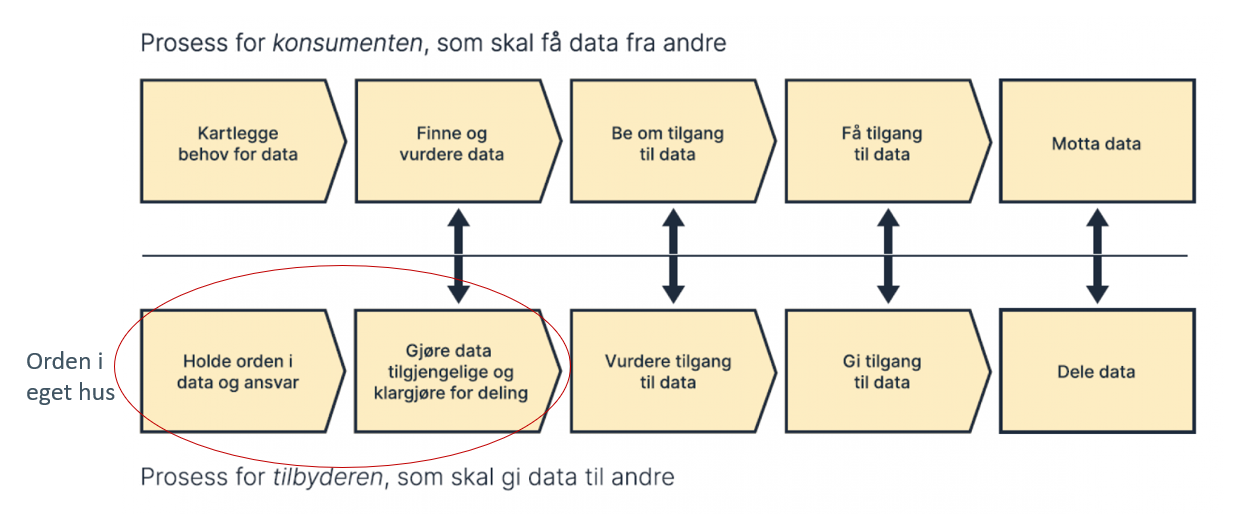
Figur 3 Verktøykassen for deling av data fra Digitaliseringsdirektoratet
Den røde ringen i Figur 3 viser de stegene hos datatilbyderen som omhandler arbeidet med å få oversikt over og tilgjengeliggjøre egne datasett, kalt «orden i eget hus». Dette arbeidet er støttet av arbeidet med informasjonsforvaltning, behandlet i neste seksjon.
4. Forvaltning av informasjon som deles på plattformen
For at datadeling skal gi best mulig verdi må data ha den kvaliteten som konsumenten behøver og forventer. Referansearkitekturen anbefaler tiltak med basis i sektorenes behov.
Vi ser først på behov for datadeling sett i henhold til type arbeidsprosess. Vi kan dele sektorenes prosesser i to kategorier, som vist i Figur 4. Administrasjons- og støtteprosesser er forholdsvis stabile, og sektorene har et mål om å standardisere disse på tvers av institusjonene. Standardiseringen gir økt effektivitet og evne til samhandling mellom institusjonene, samtidig som den gir et felles fundament for innovasjon i lærings- og forskningsprosesser. Læring og forskning skal skje på den måten studenter, undervisere og forskere mener fungerer best i hvert enkelt tilfelle. Lærings- og forskningsprosesser blir dermed dynamiske og ulike. Sektorenes to kategorier av prosesser trenger forskjellige typer støtte for datadeling.
For arbeid med administrative prosesser trenger høyere utdannings- og forskningssektorene felles begreper for opplysninger om personer, studieemner og forskningsprosjekt. Her trenger sektorene støtte for arbeid med standardisering av både begreper og prosesser som bruker dem. De standardiserte prosessene kan utføres lokalt hos institusjonene, og tilhørende data kan forvaltes lokalt.
Lærings- og forskningsprosesser har behov for delte dataressurser på tvers av institusjoner. De trenger bredest mulig tilgang til læringsobjekter og forskningsresultater. Disse prosessene trenger derfor god støtte for datadeling på tvers av institusjoner, og internasjonalt. [1]
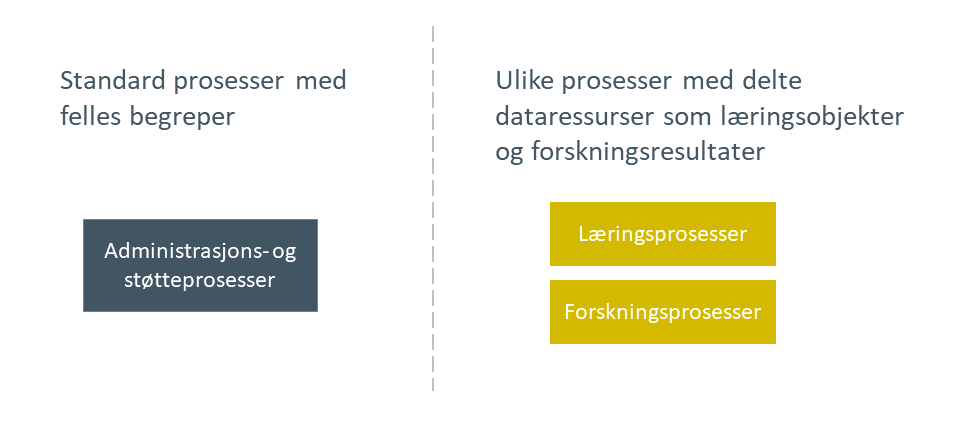
Figur 4 Strategiske valg fra Handlingsplan for digitalisering i høyere utdanning og forskning
Begge typer prosesser beskrevet over kan støttes av data i faglige kontekster vi kaller «domener», men på litt forskjellige måter for å dekke deres respektive datadelingsbehov. Figur 5. viser eksempeldomener opp på en grønn bakgrunn av informasjonsforvaltning, organisert i to forskjellige domenetyper.
De administrative domenene har ansvar for grunnleggende kontekst relatert til, for eksempel, at personer lærer i studieemner eller utfører forskning i forskningsprosjekt. Vi kaller derfor disse domenene «grunnleggende domener». Her kan vi standardisere administrasjonsprosesser, begreper og informasjonsmodeller samtidig som institusjonene kan beholde kontroll over administrasjonsdata der det er hensiktsmessig.
Domener i læring og forskning kaller vi «bruksnære domener», fordi de er definert for å støtte spesifikke arbeidsoppgaver i en brukskontekst. For eksempel vil et domene som skal støtte læring i et emne for en gruppe studenter typisk ønske å forvalte informasjon om oppgaver som hører til emnet, hvilke læringsobjekter som kan være relevant og resultater knyttet til oppgavene. Informasjonen benyttet her vil inkludere noe informasjon gjenbrukt fra grunnleggende domener, for eksempel informasjon om deltagende studenter, representert ved den grønne pilen i figur 5. Bruksnære domener støtter innovasjon i lærings eller forskningskontekst ved å tilby fleksibilitet og frihet innenfor den enkelte konteksten. Fleksibiliteten oppnås ved å avgrense domenet til der en er enig om en arbeidsmåte som passer til oppgavene.
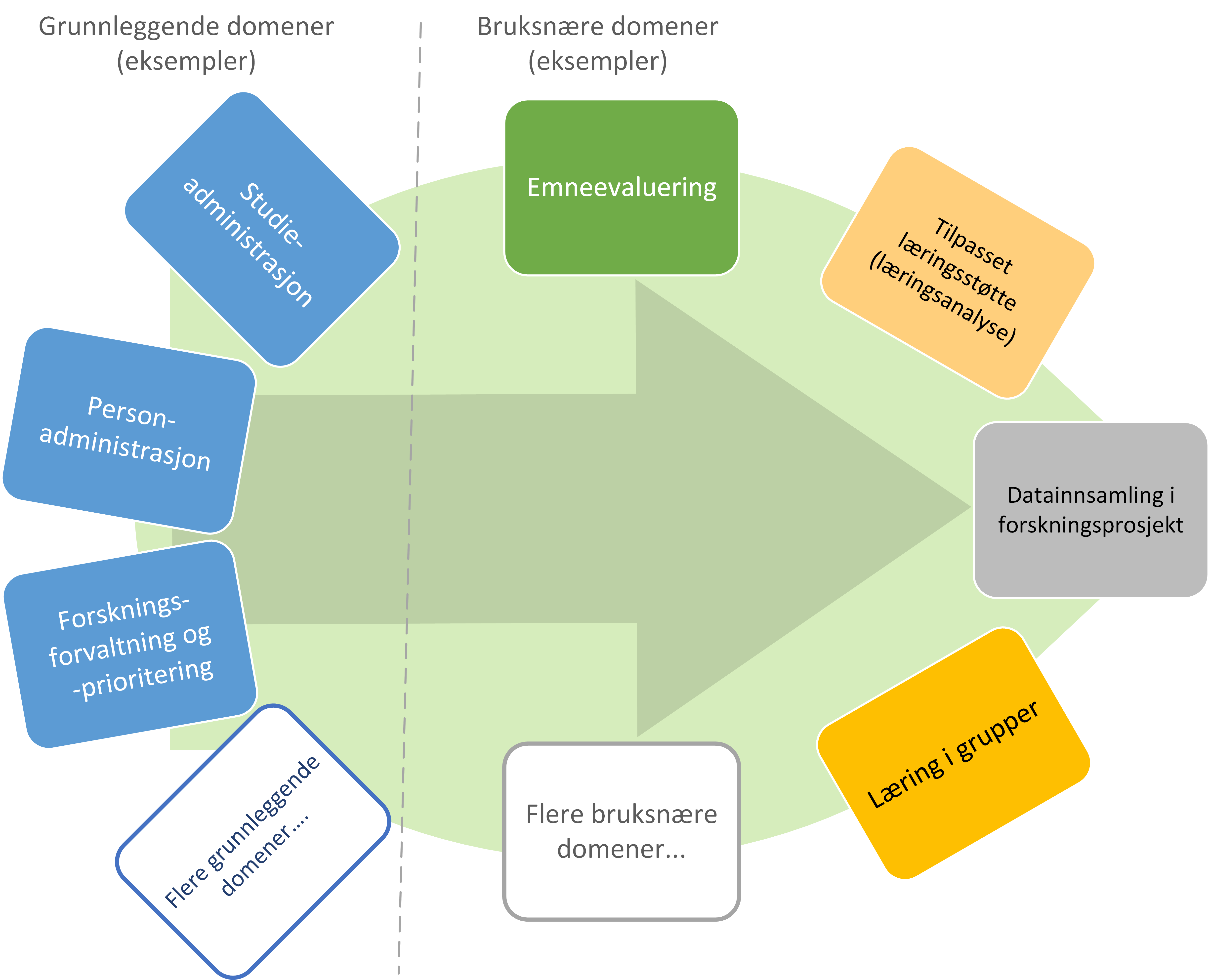
Figur 5 Domener i høyere utdanning og forskning [2]
Domenetypene "grunnleggende" og "bruksnære" gir oss et redskap for å dekke datadelingsbehov. De gir oss også et redskap for å skape kvalitet ved å klargjøre hvem som er ansvarlig for hvilke data. Referansearkitekturen anbefaler følgende roller og ansvar knyttet til informasjonsforvaltning i domener:
-
Domeneansvarlig, med ansvar for aktiviteter og tiltak innen domenet for å sikre riktig kvalitet, utnytting og sikring av informasjon i domenet
-
Begrepsansvarlig, med det faglige ansvaret for innhold av begrep som hører til domenet
Informasjonsforvaltning basert på domeneansvar forutsetter at sektorene blir enige om hvilke domener de skal forholde seg til og hvem som skal bekle rollene koblet til dem. Referansearkitekturen foreslår at koordinerende aktør (HKdir, Direktorat for høyere utdanning og kompetanse) fasiliterer en prosess for å beslutte dette i sektorene. Input til denne prosessen er pågående arbeid i sektorene innen organisasjonsevner (kapabiliteter)3 og funksjonsanalyse rettet mot arkiveringsbehov. Figur 6 viser et utdrag fra den Europeiske kapabilitetsmodellen EUNIS [3] som innspill til denne prosessen. Grunnleggende domener fra figur 5. vil være med i modellen over informasjonsdomener. Bruksdomene fra figur 5. innen læring og forskning vil være underliggende domener til henholdsvis "Leveranse av undervisning og læring" og "Forskningsproduksjon i prosjekt" i Figur 6.
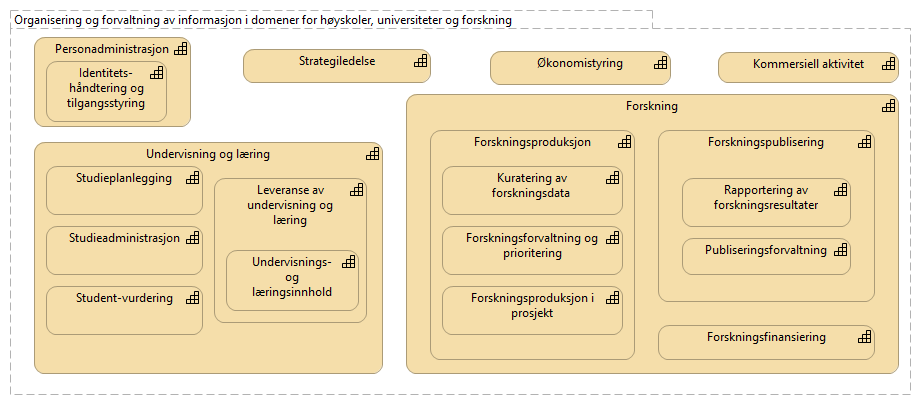
Figur 6 Forslag til informasjonsforvaltningsdomener fra EUNIS modellen
5. Økosystem for deling av data
Vår visjon er et økosystem for deling av data hvor både informasjonen som forvaltes der og datadelingsplattformen inngår. Økosystemet består av aktører i domener som samhandler ved å tilby og konsumere data. Disse aktørene utfyller hverandre i funksjon, og samhandlingen skaper større verdi enn de enkelte aktører kan klare hver for seg. Studenter, undervisere, forskere, tjenestetilbydere med flere skal både skape, tilby, bearbeide og konsumere data på nye måter som gir alle insentiv og gevinst.
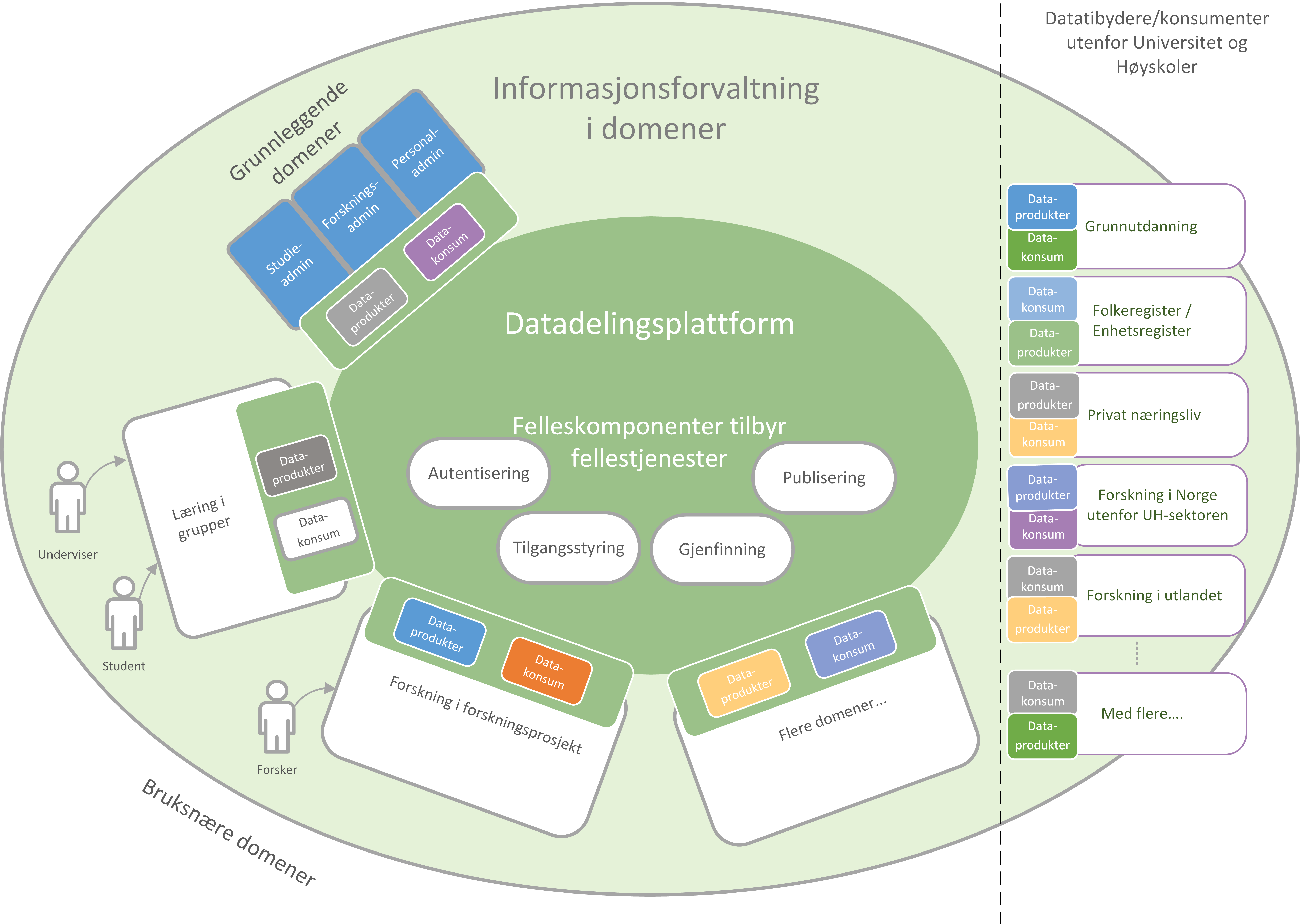
Figur 7 Et økosystem for deling av data i høyere utdanning og forskning
Figur 7 viser at aktørene kan både publisere og få tilgang til informasjonen de trenger i økosystemet. Informasjonen er forvaltet i domener, og tilgjengelig på plattformen. Dataprodukter tilgjengeliggjøres innad i, og mellom domenene i økosystemet. Domenene kan opptre som datatilbydere og datakonsumenter.